ClickHouse以性能好被大家所熟知,而一个数据库的性能优化是一个庞大的系统性工程。本文着眼于ClickHouse内部的基础数据结构,以揭露ClickHouse性能优化的冰山一角。
在软件工程中并不是所有的执行路径都需要优化,只有关键执行路径才需要花费大力气进行优化。对于数据库领域来说关键执行路径,一句话就可以概括,一个查询中对每行数据都需要执行的函数或者代码。而基础数据类型是关键执行路径上的算法的基础,所以对它们的优化对性能有重要影响。
PS:本文的讨论基于ClickHouse 24.1。
最后更新于:2024-06-03
一、基础数据类型
根据实践经验有大概一半的列是字符串类型,所以字符串是一个重要基础数据类型。ClickHouse是一个列式数据库,数据处理的过程中也是以列式进行处理,每个列的数据需要用数组表示,所以数组也是重要数据类型。
本文讨论ClickHouse的内部的重要基础数据类型:StringRef、PodArray。
二、StringRef
StringRef的工作原理类似std:string_view,它可以表示对字符串序列的引用,比如字符串str=”abcdef”,那么StringRef(str.data() + 1, 2)表示”bc”,请注意这里StringRef实际上没有对”nc”进行拷贝。
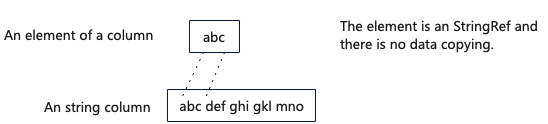
StringRef被广泛运用在ClickHouse关键执行路径中,比如:内存中对于String类型列的表示ColumnString、Aggregate和Join算子用到的关键数据结构HashMap等。下图展示了String类型列中使用StringRef,避免了数据拷贝。
因为应用广泛,所以ClickHouse对StringRef进行了深度优化。
StringRef最重要的操作是判断相等,所以判断相等的函数memequalWide是重点优化对象。如何判断两个字符串相等,ClickHouse采用了批量处理的思路,而不是逐一对比每个字符。
1. size <= 16
当字符串长度小于等于16的时候,根据字符串的长度分成以下4中情况处理。主要思路是尽量将字符串当做比较大的数据类型(整型)做比较,以节约CPU计算周期。这么做的原因是64位CPU一次计算可以对比8个字符,将其当做较大的数据类型作比较可以最大限制的减小比较的次数。
由于不是所有情况size都能被数据类型的长度整除,对比前n个字节后,在再次对比后n个字节,这里是个很巧妙的设计,因为两次对比可以完成对所有字符的比较。

2. size > 16

- 对于大于64字节的部分使用compare64,compare64是4个compare8的组合。
- 对于剩余能被16整除的部分使用compare8,compare8是一个向量比较函数,使用SSE2指令集,一次对比两个16个字符的字符串。
- 使用compare8函数对比剩余部分的的后16个字符。
3. compare8函数
通过SSE2指令集(SIMD指令)一次性对比两个16个字符的数据是否相等。
inline bool compareSSE2(const char * p1, const char * p2)
{
return 0xFFFF == _mm_movemask_epi8( // 4) translate _m128i to int32
_mm_cmpeq_epi8( // 3) 比较两个String
_mm_loadu_si128(reinterpret_cast<const __m128i *>(p1)), // 1) 将String 1加载到寄存器
_mm_loadu_si128(reinterpret_cast<const __m128i *>(p2)))); // 2) 将String 2加载到寄存器
}三、PodArray
PodArray是ClickHouse的自定义vector,ClickHouse中几乎所有的数据类型的列在内存中的表示都会用到PodArray,所以ClickHouse对PodArray也是进行了大量的优化。
绝大多数细致的优化都是针对场景的,所以首先明确PodArray设计的应用场景,它主要用于存储列式的数据,ClickHouse中列式的数据在内存中会划分为小的Chunk,默认Chunk的长度是6.5w左右,总结下来PodArray主要用于存储大量的数据的类似vector的数据结构。
1. 支持Stack内存分配
因为栈的空间是有限的,传统的动态数组结构比如std::vector,数据都是分配在堆上,这样的设计具有普适性,但是对数据的访问会有一次跳转,不利于数据cacheline的命中率。针对这一点ClickHouse提供了Stack上的内存分配方案PODArrayWithStackMemory。
其工作原理如下。首先PodArray继承了AllocatorWithStackMemory,AllocatorWithStackMemory是一个内存分配器,其特点是当需要分配的内存小于一定阈值的时候使用栈上的空间,当大于阈值的时候分配对上的空间,并把栈上的数据拷贝到堆上。
2. Padding
PaddedPodArray是带有Padding的PodArray,其左右都填充了一些空白的内存空间,这些内存空间被初始化为了0,其内存结构如下:

2.1 left padding
ClickHouse中有很多变长的数据类型,变长的数据类型指的是每个值的长度是不固定的,比如String。对于这种数据结构在存储的时候需要存储一个offset数组和一个数据数组,如下:

当需要获取某个元素的时候,需要计算元素的长度,计算方式如下:
/// Size of i-th element, including terminating zero.
size_t ALWAYS_INLINE sizeAt(ssize_t i) const
{
auto end_offset = i == 0 ? 0 : offsets[i - 1];
return offsets[i] - end_offset;
}每次都需要判断i是不是为0,if语句会大大影响CPU指令的cache命中率,并且不能触发编译器的自动向量化操作,从而影响性能。
当有了left padding后,代码可以优化为:
/// Size of i-th element, including terminating zero.
size_t ALWAYS_INLINE sizeAt(ssize_t i) const
{
return offsets[i] - offsets[i - 1];
}去掉了if,消除了对CPU指令cache命中率的影响,同时如果循环调用,可以触发编译器的自动向量化操作。
PS:CPU指令cache命中率对性能的影响可以参考:ClickHouse内幕(5)基于硬件的性能优化
PS:编译器自动向量化触发条件:requirements-for-vectorizable-loops
2.2 right padding
Right padding设计的主要作用是提升SIMD指令函数的效率并简化编码。比如:一个简单的SSE版本的memory copy函数,在没有right padding的情况下,其实现可能如下:
inline void memcpy(char * __restrict dst, const char * __restrict src, size_t n)
{
auto aligned_n = n / 16 * 16;
auto left = n - aligned_n;
while (aligned_n > 0)
{
_mm_storeu_si128(reinterpret_cast<__m128i *>(dst),
_mm_loadu_si128(reinterpret_cast<const __m128i *>(src)));
dst += 16;
src += 16;
aligned_n -= 16;
}
::memcpy(dst, src, left);
}但是如果dst和src各有15个byte的right padding,那么实现可以优化为如下:
inline void memcpy(char * __restrict dst, const char * __restrict src, size_t n)
{
while (n > 0)
{
_mm_storeu_si128(reinterpret_cast<__m128i *>(dst),
_mm_loadu_si128(reinterpret_cast<const __m128i *>(src)));
dst += 16;
src += 16;
n -= 16;
}
// 这里无需额外处理结尾部分
}3. emplace_back函数
PodArray的emplace_back函数,直接在末尾的内存空间上构建要插入的对象,相对提前构建然后在拷贝的方式减小了一次内存拷贝的开销。这个优化方式跟std::vector的emplace_back函数类似。
template <typename... Args>
void emplace_back(Args &&... args) /// NOLINT
{
if (unlikely(this->c_end + sizeof(T) > this->c_end_of_storage))
this->reserveForNextSize();
new (t_end()) T(std::forward<Args>(args)...); /// 在末尾构建对象,减少了数据拷贝的开销
this->c_end += sizeof(T);
}在创建对象的时候使用了placement new operator,其允许在指定内存地址创建对象,关于placement new operator请参考:stackoverflow
本作品采用 知识共享署名 4.0 国际许可协议 进行许可, 转载时请注明原文链接。