ClickHouse utilizes a unique clustered index, meaning that data within a Part is ordered according to the order by keys. In the entire query plan, if an operator can effectively utilize the orderliness of the input data, the execution performance of the operator will see significant improvements. This article discusses the optimization methods for query operators in ClickHouse based on indexes.
In the entire query plan, the operators Sort, Distinct, and Aggregation have the following characteristics compared to other operators such as filtering and projection: 1. The operator needs to maintain state in memory, leading to high memory costs; 2. The operator has high computational costs; 3. The operator will block the execution pipeline, only outputting data downstream after all computations are complete. Therefore, these operators are often the bottlenecks in the entire query.
This article discusses in detail the impact on computation, memory, and pipeline blocking before and after the query optimization of the three operators based on indexes.
Last updated: 2024-04-08
Preparation Before Experiments
The subsequent discussion is primarily based on experiments.
CREATE TABLE test_in_order
(
`a` UInt64,
`b` UInt64,
`c` UInt64,
`d` UInt64
)
ENGINE = MergeTree
ORDER BY (a, b);There are a total of 3 parts in the table, with each part containing 4 rows of data.
P.S.: Users can disable background merges before inserting data to prevent parts from being merged into one. If parts are merged into one, it will affect the query parallelism, which might impact the experiment. The following query can be used to disable background merges: system stop merges test_in_order.
1. Sort Operator
If the ORDER BY field in an ORDER BY query matches the prefix columns of the table’s ORDER BY keys, the query can be optimized based on the ordered nature of the data.
1.1 Implementation of the Sort Operator
First, let’s look at scenarios where the primary key’s order cannot be utilized, i.e., when the ORDER BY fields in the query do not match the prefix columns of the table’s ORDER BY keys. For example, consider the following query:
query_1: EXPLAIN PIPELINE SELECT b FROM read_in_order ORDER BY b ASCThe query plan is as following:
┌─explain───────────────────────────────┐
│ (Expression) │
│ ExpressionTransform │
│ (Sorting) │
│ MergingSortedTransform 3 → 1 │
│ MergeSortingTransform × 3 │
│ LimitsCheckingTransform × 3 │
│ PartialSortingTransform × 3 │
│ (Expression) │
│ ExpressionTransform × 3 │
│ (ReadFromMergeTree) │
│ MergeTreeThread × 3 0 → 1 │
└───────────────────────────────────────┘The sorting algorithm consists of three Transforms, which are:
PartialSortingTransformsorts individual Chunks;MergeSortingTransformsorts a single stream;MergingSortedTransformmerges multiple ordered streams to perform a global sort-merge.
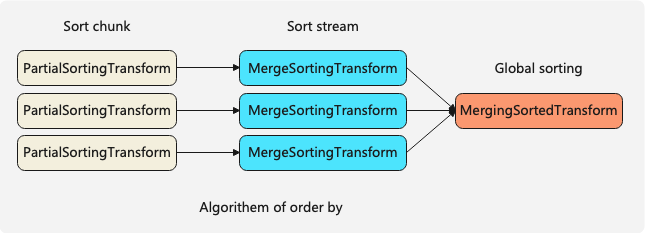
If the ORDER BY fields in the query match the prefix columns of the table’s ORDER BY keys, the query can be optimized based on the data’s ordered characteristics. The optimization switch for this is: optimize_read_in_order.
1.2 Queries Matching Index Columns
The following query’s ORDER BY fields match the prefix columns of the table’s ORDER BY keys.
query_3: EXPLAIN PIPELINE SELECT b FROM test_in_order ORDER BY a ASC, b ASCSETTINGS optimize_read_in_order = 0 -- close read_in_orderLet’s examine the pipeline execution plan for the ORDER BY statement.”
┌─explain───────────────────────────┐
│ (Expression) │
│ ExpressionTransform │
│ (Sorting) │
│ MergingSortedTransform 3 → 1 │
│ MergeSortingTransform × 3 │
│ (Expression) │
│ ExpressionTransform × 3 │
│ (ReadFromMergeTree) │
│ MergeTreeThread × 3 0 → 1 │
└───────────────────────────────────┘The ORDER BY operator’s algorithm in this case is as follows:
- First,
MergeSortingTransformsorts the input stream. - Then,
MergingSortedTransformmerges the multiple sorted streams and outputs a single globally sorted stream, which is the final sorted result.
There is a question regarding the query plan when the read_in_order optimization is disabled. The system directly assumes that the input to MergeSortingTransform is ordered within each Chunk. This is actually an implicit optimization because the ORDER BY fields in the query match the prefix columns of the table’s ORDER BY keys, ensuring that the data within each Chunk is inherently ordered.
1.3 Enable optimize_read_in_order
┌─explain──────────────────────────┐
│ (Expression) │
│ ExpressionTransform │
│ (Sorting) │
│ MergingSortedTransform 3 → 1 │
│ (Expression) │
│ ExpressionTransform × 3 │
│ (ReadFromMergeTree) │
│ MergeTreeInOrder × 3 0 → 1 │
└──────────────────────────────────┘1.4 Analysis
After enabling optimize_read_in_order:
- For computation: The algorithm includes only one
MergingSortedTransform, omitting the step of sorting within individual streams. - For memory usage: Since
MergeSortingTransformis the most memory-intensive step, the optimization can save a significant amount of memory. - For pipeline blocking:
MergeSortingTransformcan block the entire pipeline, so the optimization also eliminates this blocking.
2. Distinct Operator
If the distinct fields in a DISTINCT query match the prefix columns of the table’s ORDER BY keys, the query can be optimized based on the ordered nature of the data. The optimization can be enabled using the optimize_distinct_in_order setting. This can be demonstrated through the following experiment:
2.1 Implementation of the Distinct Operator
Viewing the Pipeline Execution Plan for a DISTINCT Query
query_2: EXPLAIN PIPELINE SELECT DISTINCT * FROM woo.test_in_order SETTINGS optimize_distinct_in_order = 0 -- disable optimize_distinct_in_order┌─explain─────────────────────────────┐
│ (Expression) │
│ ExpressionTransform │
│ (Distinct) │
│ DistinctTransform │
│ Resize 3 → 1 │
│ (Distinct) │
│ DistinctTransform × 3 │
│ (Expression) │
│ ExpressionTransform × 3 │
│ (ReadFromMergeTree) │
│ MergeTreeThread × 3 0 → 1 │
└─────────────────────────────────────┘The DISTINCT operator uses a two-stage approach. First, the initial DistinctTransform performs a preliminary distinct operation internally with a parallelism of 3, meaning that you can think of it as having 3 threads executing simultaneously. Then, the second DistinctTransform performs the final distinct operation.
The computation method for each DistinctTransform is as follows: first, a HashSet data structure is constructed. Then, based on the HashSet, a filter mask is built (if the current key exists in the HashSet, it is filtered out). Finally, the unnecessary data is filtered out.
2.2 Enable optimize_distinct_in_order
You can see that the preliminary distinct and final distinct operations use different transforms, namely DistinctSortedStreamTransform and DistinctTransform.
DistinctSortedStreamTransform: This transform performs the distinct operation on data within a single stream. Since the distinct columns match the prefix columns of the table’s ORDER BY keys, and the scan operator reads data such that each stream reads from only one part, the input data for each distinct transform is ordered. Therefore, the distinct algorithm is as follows:
Algorithm for DistinctSortedStreamTransform 1:
In the Transform, the last input data is kept as the state. For each new input data, if it is the same as the retained state, it is ignored. If it is different, the previous state is output to the previous operator, and the current data is retained as the new state. This algorithm significantly reduces both the time and space complexity for globally deduplicating within the entire stream.
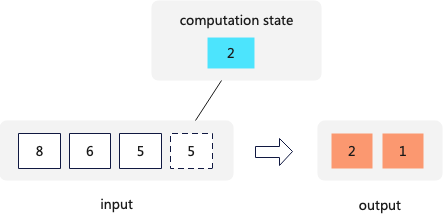
DistinctSortedStreamTransform Algorithm 2 (Used by ClickHouse):
In this algorithm, the Transform processes each chunk (the basic unit of data processing in ClickHouse, typically around 65,000 rows). The steps are as follows:
- Divide Data into Ranges: First, the transform identifies and divides the same data into multiple ranges within the chunk.
- Set a Mask Array: A mask array is set up to mark which rows are duplicates.
- Remove Duplicate Data: Using the mask array, the transform removes the duplicate data from the chunk.
- Return the Processed Chunk: Finally, the transform returns the chunk with the duplicates removed.
This method ensures efficient deduplication within each chunk, leveraging the ordered nature of the data to streamline the process.
2.3 Analysis
Enabling optimize_distinct_in_order optimizes the first stage of the DISTINCT operation by switching from a hash-based filtering algorithm to one that handles consecutive identical values.
- Computation: The optimized algorithm eliminates the need for hash calculations but introduces equality checks instead. Depending on the dataset’s cardinality, each approach has its pros and cons.
- Memory Usage: The optimized algorithm does not require storing a
HashSet. - Pipeline Blocking: Both before and after optimization, the pipeline will not be blocked.
3. Aggregating Operator
If the GROUP BY query’s group by fields match the prefix columns of the table’s order by keys, the query can be optimized based on the ordered nature of the data. The optimization switch for this is optimize_aggregation_in_order.
3.1 Implementation of the Aggregating Operator
To view the pipeline execution plan of a GROUP BY statement.
query_4: EXPLAIN PIPELINE SELECT a FROM test_in_order GROUP BY a SETTINGS optimize_aggregation_in_order = 0 -- disable read_in_order optimization┌─explain─────────────────────────────┐
│ (Expression) │
│ ExpressionTransform × 8 │
│ (Aggregating) │
│ Resize 3 → 8 │
│ AggregatingTransform × 3 │
│ StrictResize 3 → 3 │
│ (Expression) │
│ ExpressionTransform × 3 │
│ (ReadFromMergeTree) │
│ MergeTreeThread × 3 0 → 1 │
└─────────────────────────────────────┘The overall algorithm for the aggregation operator is not fully displayed in the execution plan. At a macro level, it employs a two-stage aggregation algorithm. The complete algorithm is as follows:
- AggregatingTransform performs the initial aggregation. This step can be executed in parallel.
- ConvertingAggregatedToChunksTransform performs the second stage of aggregation.
(PS: For simplicity, the explanation ignores the introduction of two-level HashMap and spill to disk mechanisms.)
3.2 Enable optimize_aggregation_in_order
The following is the query plan:
┌─explain───────────────────────────────────────┐
│ (Expression) │
│ ExpressionTransform × 8 │
│ (Aggregating) │
│ MergingAggregatedBucketTransform × 8 │
│ Resize 1 → 8 │
│ FinishAggregatingInOrderTransform 3 → 1 │
│ AggregatingInOrderTransform × 3 │
│ (Expression) │
│ ExpressionTransform × 3 │
│ (ReadFromMergeTree) │
│ MergeTreeInOrder × 3 0 → 1 │
└───────────────────────────────────────────────┘When the optimize_aggregation_in_order setting is enabled, the aggregation algorithm consists of three steps:
- AggregatingInOrderTransform performs preliminary aggregation by grouping consecutive identical keys within a stream. After this pre-aggregation, there will be only one entry for each unique key within the current stream.
- FinishAggregatingInOrderTransform re-groups data received from multiple streams to ensure that the data in the output chunks is ordered. For instance, if the maximum
group bykey in the previous chunk is 5, the current chunk being output will not contain any data with keys greater than 5. - MergingAggregatedBucketTransform performs the final merge aggregation.
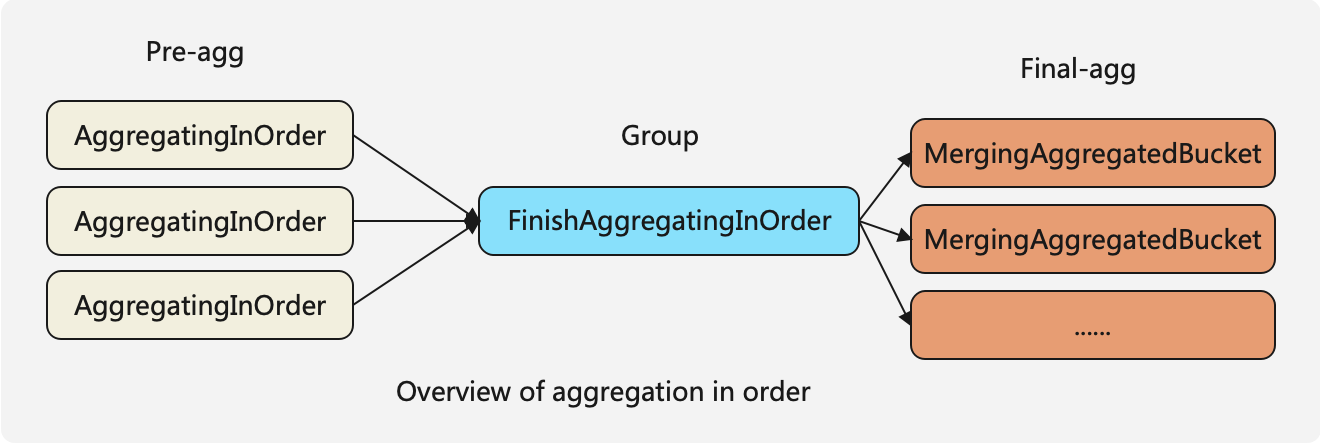
The grouping algorithm for the FinishAggregatingInOrderTransform works as follows:
Assume there are 3 streams. The current operator will maintain 3 Chunks, one for each stream. The process is as follows:
- Initially, the operator selects the last entry from each of the 3 Chunks and identifies the minimum value among them. For example, if the minimum value is 5, it will then proceed to the next step.
- The operator then extracts all data from the 3 Chunks that is less than this minimum value (in this case, 5). These data entries are processed and output together.
- This process is repeated iteratively. If a Chunk is exhausted (i.e., all its data entries have been processed), a new Chunk is fetched from the corresponding stream.
By following this algorithm, the operator ensures that the data in the output chunks remains ordered.
This algorithm ensures that the maximum value of the Chunk output by FinishAggregatingInOrderTransform is less than the minimum value of the next Chunk, facilitating optimization in subsequent steps.
3.3 Analysis
Enabling optimize_aggregation_in_order primarily optimizes the first stage of aggregation, transitioning from a HashMap-based algorithm to one based on consecutive identical values.
- Computation: The optimized algorithm reduces the number of hash calculations but increases the number of equality checks. Depending on the size and distribution of the data set, this can have varying impacts on performance.
- Memory Usage: There is no significant difference in memory usage before and after the optimization.
- Pipeline Blocking: There is no significant difference in pipeline blocking before and after the optimization.
4. Summary of In-order Optimization
In the entire query plan, the Sort, Distinct, and Aggregation operators are often the bottlenecks of the query, making them worthy of deep optimization. ClickHouse optimizes the algorithms of these operators by leveraging the ordered nature of the input data, achieving varying degrees of optimization in terms of computation, memory usage, and pipeline blocking.
The viewpoints expressed in this article are based on reading the ClickHouse source code and the author’s understanding. If you have any questions, feel free to reach out for discussion.
This work is licensed under a Creative Commons Attribution 4.0 International License. When redistributing, please include the original link.