优化器的职责是将一个未经优化的本地的逻辑执行计划,生成一个优化过后的分布式的物理执行计划。整个搜索过程由搜索框架完成。现代优化器通常基于Cascades风格,核心模块通常包含了核心搜索算法、Memo、Rules、属性计算、统计信息、代价模型等。ClickHouse优化器的研发基于论文Clumbia和Orca,本文描述其核心思路。
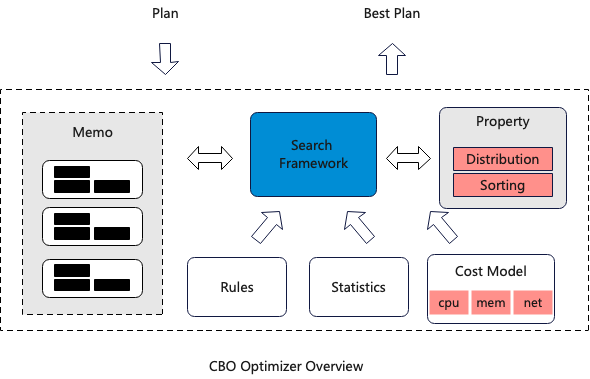
本文尝试通过一个例子直观的展示每个模块的核心工作原理。下文的阐述基于如下SQL:
select a, count() from t1 where b > 10 group by a
一、核心数据结构
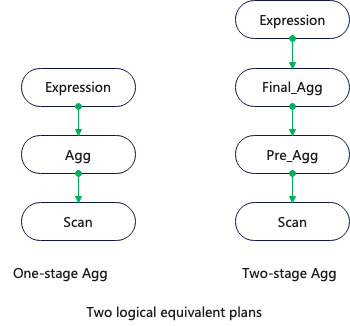
Memo是优化器存储执行计划的核心数据结构,由于执行计划根据优化规则、属性、算法会衍生出很多等价的执行计划,如果每个执行计划独立存储会占用大量的存储空间,比如:Agg算子有one-stage和two-stage两个等价的执行计划
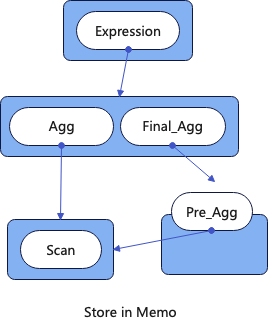
放到Memo中后如下,其中蓝色的表示Group,每个Group可以包含多个等价的执行计划,可以看到One-Stage的Agg和两阶段的Final_Agg在同一个Goup中。从下图中可以看到Memo相比独立存储的方式避免了重复算子的存储,节约了大量的存储空间。
二、核心搜索算法
优化器的核心搜索算法,是由动态规划实现的,我们将优化器搜索最优执行计划的问题抽象如下:给定多个等价的执行计划树,找出执行代价最小的那一个。根据上文的描述我们需要使用Memo来降低存储空间,那么问题可以细化为:找出Root Group G3的最优执行计划。
G3的最优执行计划的关键是G2的最优执行计划,G2的最优执行计划是:min(Agg + G1, Final_agg + G4),依次类推。归纳出寻找Group的最优执行计划符合动态规划最优子结构的特性。其解方程如下:
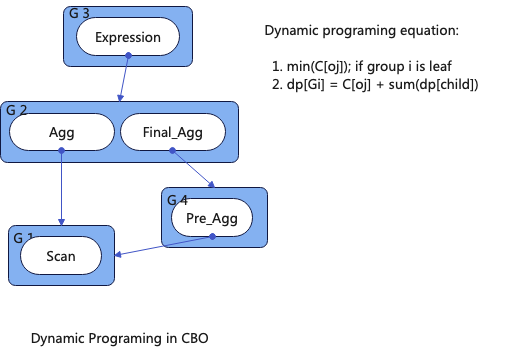
如果Group是叶子节点则其最优解是其包含的等价的算子的代价最小的那个,即:min(C[oj]);如果其不是叶子节点,那么Group i的最优解dp[Gi],是以其包含的等价算子为Root的执行计划的最优解,即:dp[Gi] = C[oj] + sum(dp[child])。
以上描述了优化器最核心的数据结构和搜索算法,到这里聪明的你可能已经可以实现一个简化版的优化器的搜索框架了。
但是优化器是一个非常复杂的组件,在以上核心算法上有一些约束和额外的逻辑,Cascades风格的优化器核心模块包还含了算子、Rules、属性计算、统计信息、代价模型等。接下来概括每个模块的核心工作原理。
三、初始化Memo
优化器工作的第一步是将原始执行计划拷贝到Memo中,下图展示了初始化Memo的过程,整个过程是一对一拷贝。其中绿色的线表示查询计划的节点之间的关系,蓝色的表示Memo Node(也被称为Group Node)跟Memo Group的关系,请注意Memo中Node的child是Group而不在是Node,这一点对后文的理解很重要。
完成初始化后,我们不在需要关注绿色线的关系,只需要关注蓝色线的关系。在最后完成优化后根据蓝色关系和两个映射表构建最终的最优执行计划。
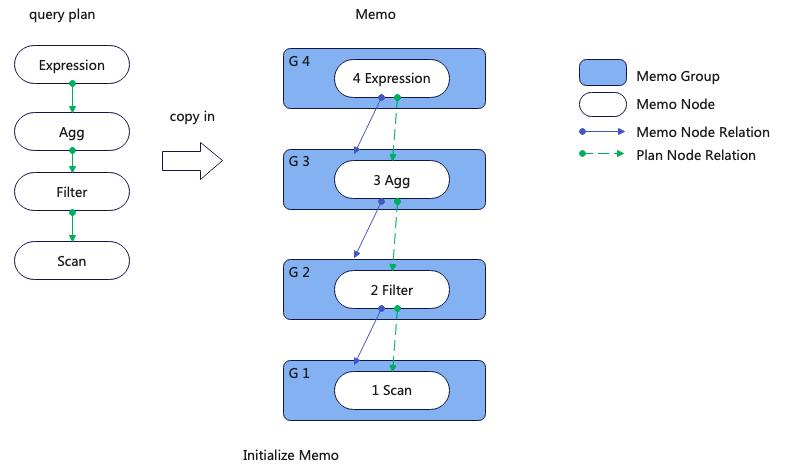
上图中蓝色的图标表示Goup,每个Group都有唯一ID,白色的图标表示GroupNode,也有全局唯一ID。
四、Apply Rules
1.什么是Rules
Rules在整个搜索框架中是核心组件,它可以通过部分执行计划衍生出新的等价的执行计划。比如本例中一阶段聚合Agg可以衍生出两阶段的聚合 Final_Agg – Pre_Agg。
Rule有两类一类是Physical Rules用于将逻辑算子转换成物理算子,比如:Join -> [sort merge join, hash join];另一类是Logical Rules用于衍生逻辑等价的执行计划,比如:Join结合律。在ClickHouse执行计划中的算子没有严格的Logical和Physical的区别,类似一种混合的形式,所以错略的来说本文中讨论的规则都是Logical的。
2.Rules的作用
Rules主要的作用是衍生出新的逻辑等价的执行计划,在本例中可以应用SplitAggregation Rule衍生出两阶段的Agg,应用该Rule后的Memo如下:

3.Memo copy-in
请注意新生成的两个GroupNode Final_Agg和Pre_Agg,其中Final_Agg所代表的子执行计划与Agg是等价的所以应该放到跟Agg同一个Group中,而Pre_Agg则需要新建一个Group。
五、属性计算
1.什么是属性?
在优化器中属性往往有两种一种是Logical属性表示算子输入和输出的Header,也就是列名和数据类型,另一种是Physical属性也是本文需要讨论的。Physical属性主要有两种一种是Distribution表示数据在分布式系统中是如何分布的;另一种是Sorting表示数据是如何排序的。属性计算重点关注Distribution属性,它有如下6种类型:
- Any:任何属性,不是具体的属性,可以表示任何其它属性
- Singleton:数据只存在一个节点上
- Distributed:数据存在于多个节点上,不是具体的属性,可以表示除Singleton外的其它属性
- Straight:数据存在于多个节点上,但没有特别的离散方式
- Hashed:数据按照某些key离散到多个节点上
- Replicated:在多个节点上具有全量数据
属性的关系如下图所示:
Any
/ \
Distributed Singleton
/ | \
Straight Replicated Hashed
论文Orca中是4种,在ClickHouse 优化器中我们新增了Distributed和Straight两种,用于处理有多个Children的GroupNode的属性,主要动机是避免选择出Singleton和Distributed共存的属性组合,由于属性计算非常复杂,这里不详细展开。
2.属性计算的作用
2.1算子间数据如何传输
在本例中Filter在所有的节点上执行,Agg只能在一个节点上执行,那么Filter就需要将数据全部传输到Agg所在的节点上,所以我们需要再Filter后增加一个Exchange算子用于传输数据。属性计算会计算出算子间数据如何传输,作为插入Exchange算子的依据。
2.2 衍生等价执行计划
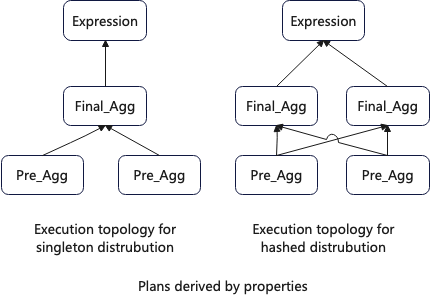
同时属性计算还可以衍生出等价的执行计划,比如:Final_Agg对Child的Required属性可以有Singleton和Hashed两种,对应以下不同的执行拓扑结构。
3.属性计算的宏观思路
宏观思路是一种Top-Down的,即从上到下请求,从下到上计算:
- 首先衍生出每个GroupNode的Children(Group)的Required Properties 列表,比如:某些算子对它的Children的属性有特别的要求,比如:Broadcast Join要求Right Child的Distribution是Replicated,Shuffle Join要求Left和Right Childred的Distribution是Hashed。
- 然后计算Children Group中的GroupNode的输出属性
- 根据Children GroupNode的输出属性计算当前Node的输出属性
- 如果计算出来的GroupNode的输出属性不满足Required属性,则需要插入Exchange节点以满足Required属性。
下面一一介绍整个计算步骤
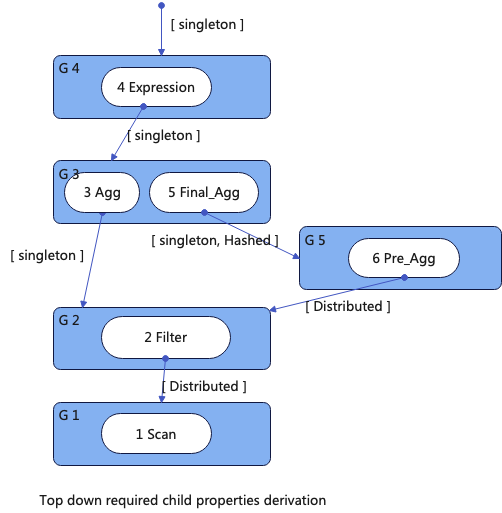
4.衍生GroupNode的Required属性列表
Required 属性列表有两层含义:1.Child的输出属性必须满足该属性要求,比如:Required是Distributed,那么下层就不能输出Singleton(PS:属性的满足关系请参考上文2.1);2.衍生等价执行计划(参考上文2.2)
衍生GroupNode的Required 属性列表,采用从上到下的方式进行衍生,因为不需要依赖下方的输入,所以直接在遍历过程进行计算。
5.计算当前GroupNode的输出属性
计算当前GroupNode的输出属性采用Bottom-Up的方式,因为当前GroupNode的属性需要依赖其Children的属性,比如:Scan输出属性是Straight,那么Filter的输出也是Straight,除去特殊算子比如Exchange或者Sorting,其他算子大多数不会改变输入的属性,所以大多数情况下算子的输入属性就决定了其输出属性。
同时这里计算出来的输出属性,需要满足其Required属性,在上一步Required属性衍生步骤中,Filter 和 Pre_Agg的Required属性都是Singleton但是其输出都是Straight的,所以这里发生了属性不满足的情况。
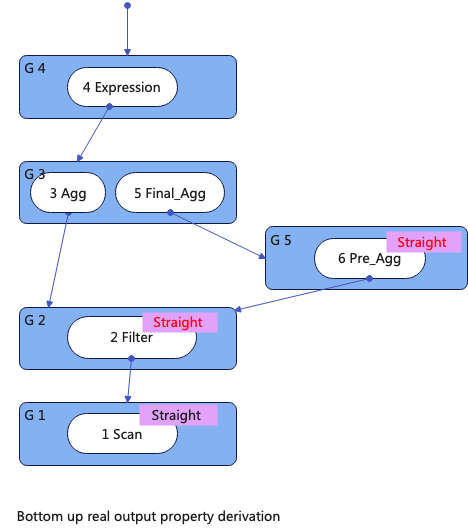
6.Enforcing Exchange
如果属性不满足,则需要插入Exchange,也一过程也被称作Enforcing Exchange。比如上图中的Filter 和 Pre_Agg,其的Required属性都是Singleton但是其输出都是Straight。下图展示了插入Exchange后的Memo。
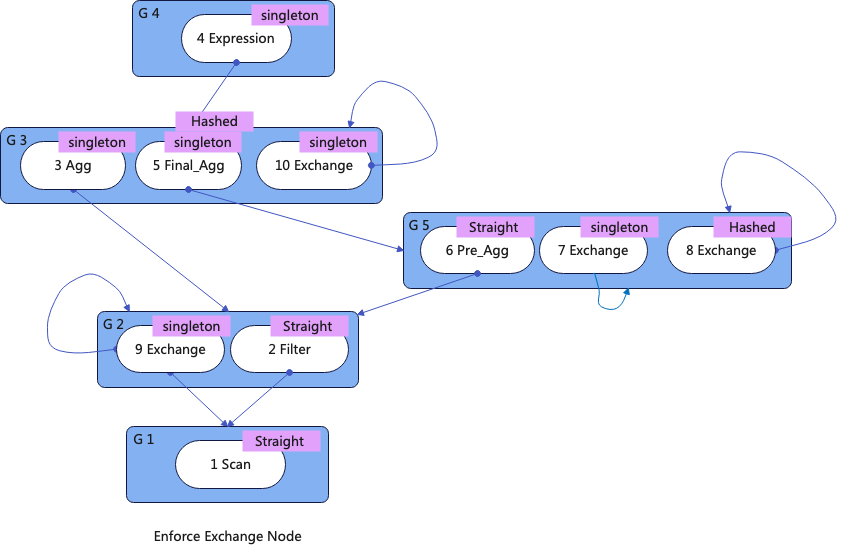
插入的Exchange与Exchange的输入Node在同一个Group,并且其Child Group指向当前Group,至此完成了属性的计算和Enforcing Exchange。
六、衍生统计信息和代价
1.统计信息(Statistics)
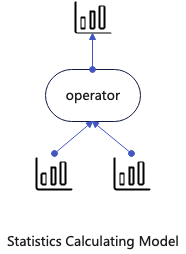
统计信息是一个数据集的概览,比如一个表或者查询计划中的一个算子。统计信息通常包含如下信息:行数、行平均大小,每个列的基数集、最大最小值、空值的比例等,当前统计信息的实现中只包含这些基础信息。统计信息中还可以使用一些复杂的数据结构CoutMinSketch、直方图等用于更精确到额评估。
每个GroupNode的输出统计信息计算需要依赖其Children的输出统计信息,其计算模型类似下图:
对于整个执行计划来说宏观的计算思路是从上到下请求从下到上计算,如下图所示
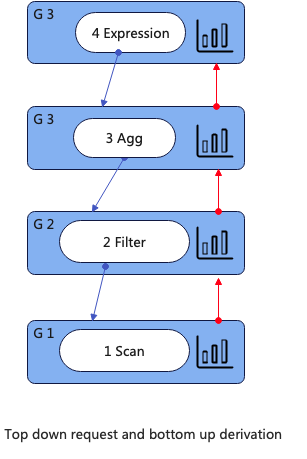
在所有的算子中需要特别注意Filter、Join、Aggregating的统计信息,因为他们会改变输入的数据量,同样这里不在展开。
2.代价(Cost)
代价指的是执行GroupNode所需要的代价,从系统执行所需要的资源的角度来说分成了三类:cpu、memory、network。每个GroupNode的代价都由这三部分组成,每个算子代价的计算需要Children的统计信息作为输入和并且根据当前算子的算法生成一个计算公式,计算出来的结果包含cpu、memory、network三类,然后加权求和作为最终算子的代价。
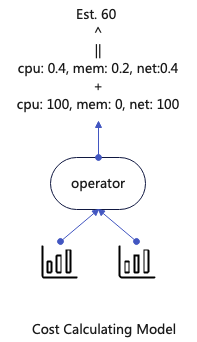
宏观上代价的衍生类似统计信息也是采用从上到下请求从下到上计算的思路。
七、计算最佳子执行计划
1.计算思路
优化器采用动态规划的思路,具体请参考本文第二节,计算最佳子执行计划其实也就是动态规划的解方程,但是在优化器的场景中其算法更复杂,需要将规则、属性计算、统计信息、代价全部包含在搜索框架中,其可以抽象为如下步骤:
- Optimize Group:目标是寻找出该
Group内每个Required属性对应的最佳GroupNode - Optimzie every GroupNode in group:目标是寻找出该GroupNode的每个输出属性对应的最佳子查询计划,具体为:最佳子执行计划的输出属性及其代价
- Apply Rules:衍生等价的子执行计划(可能产生新的Group)
- Derive Statistics:计算统计信息
- 属性计算:计算GroupNode的Required和实际Output属性
- 代价计算:计算每个GroupNode的代价最低的执行计划
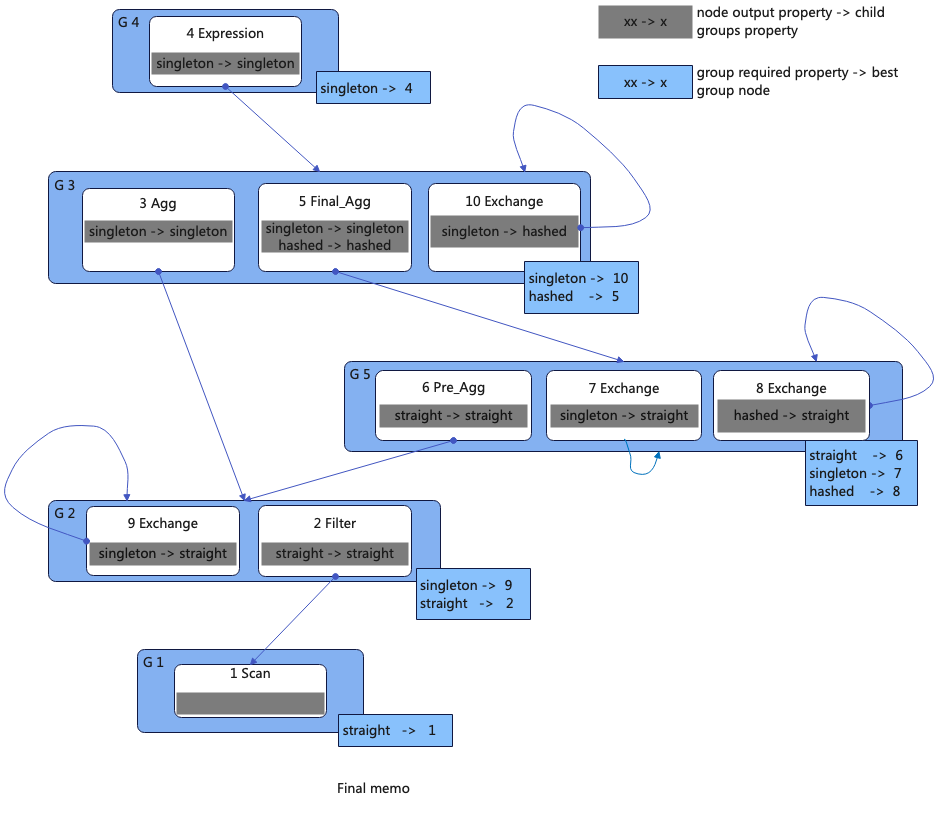
2.Memo状态
下图展示了搜索完成后的Memo,其中包含了两个重要的映射表,其中蓝色的表示每个Group的Required属性跟满足其属性要求的代价最低的GoupNode的映射;灰色的表示每个GroupNode的输出属性和它的Children属性的映射关系。
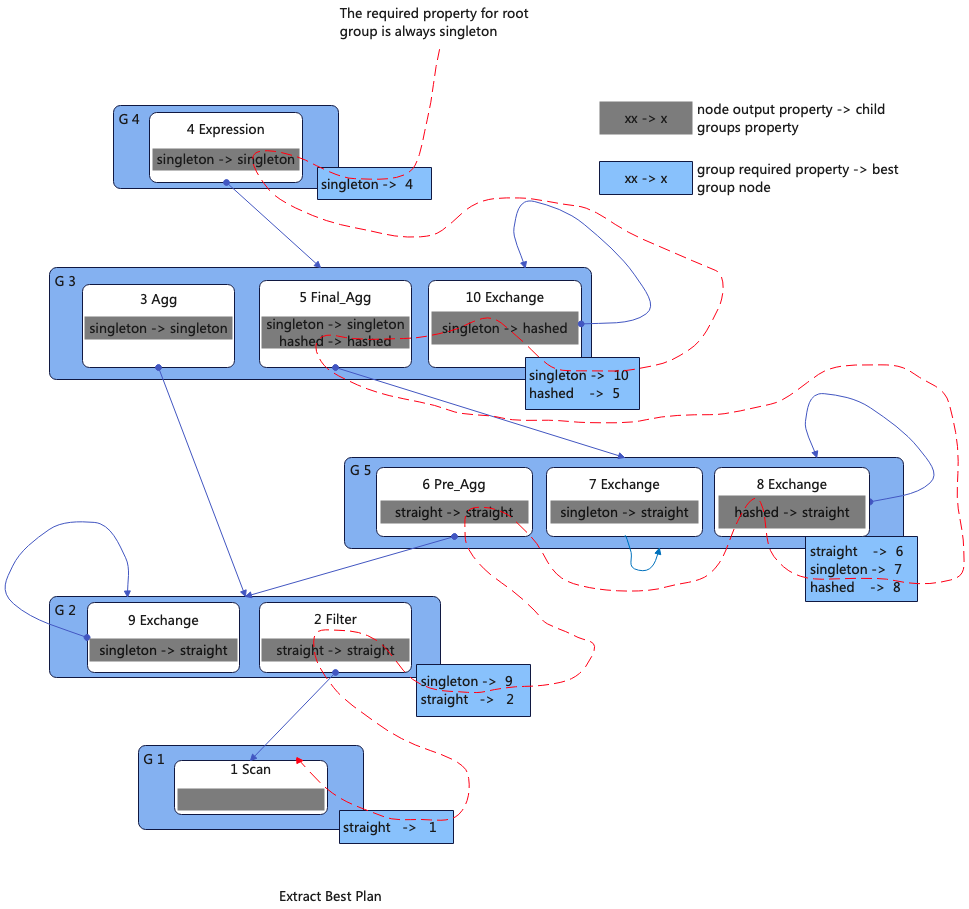
八、生成最佳执行计划
通过这两个映射关系可以得到最佳的执行计划,下图非常清晰的展示了具体的算法。1. Root Goup的Required属性是Singleton的,通过蓝色的映射表获得最佳的GroupNode是4号;2. 然后通过4号GroupNode的灰色映射关系得到它的Child Group的属性是Singleton的;3. 通过其Child Group(G3)的蓝色映射关系定位到Singleton对应10号GroupNode;4. 通过10号GroupNode定位到G3的Child Group(G5)的输出属性应该是Hashed。5. 依次类推生成完整的最优执行计划。
九、小结
本文通过一条SQL简要概括了ClickHouse优化器的核心搜索算法,包含:核心的数据结构Memo和动态规划的搜索算法,也介绍了优化器的核心组件:Rules、属性计算、统计信息、代价和核心检索算法等部分。以及Top-Down的思路(从上到下请求,从下到上计算)在整个框架中的应用。
本作品采用 知识共享署名 4.0 国际许可协议 进行许可, 转载时请注明原文链接。