记录一次线上ClickHouse字典大小优化实践,优化前后存储空间从75GB降到26.5GB。
问题现象
线上3个集群字典dict.active_sku_dict太大,集群中每个节点2kw条数据,占用内存75GB,服务器内存使用率太高,导致导数任务失败。目前字典已经按照分片切分,并且业务上不能精简数据条数。所以只能按照减小字典大小的方向优化。
问题分析&解决方案
字典创建语句
CREATE DICTIONARY dict.active_sku_dict
(
`item_sku_id` UInt64,
`sku_name` String,
`spu_id` String,
`shop_id` String,
`shop_name` String,
`itm_frst_catg_cd` String,
`itm_frst_catg_name` String,
`itm_scnd_catg_cd` String,
`itm_scnd_catg_name` String,
`itm_thrd_catg_cd` String,
`itm_thrd_catg_name` String,
`itm_fourth_catg_cd` String,
`itm_fourth_catg_name` String,
`sub_brand_cd` String,
`sub_brandname` String,
`brand_cd` String,
`brandname` String,
`bu_id` String,
`bu_name` String,
`dept_id_1` String,
`dept_name_1` String,
`dept_id_2` String,
`dept_name_2` String,
`dept_id_3` String,
`dept_name_3` String,
`dept_id_4` String,
`dept_name_4` String,
`pur_erp` String,
`pur_name` String,
`purchaser_erp_acct` String,
`purchaser_erp_name` String,
`purchaser_control_erp_acct` String,
`purchaser_control_erp_name` String,
`cate_oper_erp_acct` String,
`cate_oper_erp_name` String,
`cate_bu_id` String,
`cate_bu_name` String,
`cate_dept_id_1` String,
`cate_dept_name_1` String,
`cate_dept_id_2` String,
`cate_dept_name_2` String,
`cate_dept_id_3` String,
`cate_dept_name_3` String,
`cate_dept_id_4` String,
`cate_dept_name_4` String,
`cate_dept_id_5` String,
`cate_dept_name_5` String,
`cate_dept_id_6` String,
`cate_dept_name_6` String
)
PRIMARY KEY item_sku_id
SOURCE(CLICKHOUSE(HOST localhost PORT 9600 USER 'xxx' PASSWORD 'xxx' DB 'dict' TABLE 'active_sku_local'))
LIFETIME(MIN 0 MAX 0)
LAYOUT(HASHED())通过分析大概有2点可以优化
- 很多ID类的字段类型选择的是String,可以改为整数类型
- 有部分字段没有用到,可以删除这部分字段
优化效果
优化后的字典
CREATE DICTIONARY dict.active_sku_test_dict
(
`item_sku_id` UInt64,
`spu_id` UInt64,
`shop_id` UInt64,
`itm_frst_catg_cd` UInt64,
`itm_scnd_catg_cd` UInt64,
`itm_thrd_catg_cd` UInt64,
`itm_fourth_catg_cd` UInt64,
`sub_brand_cd` UInt64,
`brand_cd` UInt64,
`bu_id` UInt64,
`dept_id_1` UInt64,
`dept_id_2` UInt64,
`dept_id_3` UInt64,
`dept_id_4` UInt64,
`pur_erp` String,
`purchaser_erp_acct` String,
`purchaser_control_erp_acct` String,
`cate_oper_erp_acct` String,
`cate_bu_id` UInt64,
`cate_dept_id_1` UInt64,
`cate_dept_id_2` UInt64,
`cate_dept_id_3` UInt64,
`cate_dept_id_4` UInt64,
`cate_dept_id_5` UInt64,
`cate_dept_id_6` UInt64
)
PRIMARY KEY item_sku_id
SOURCE(CLICKHOUSE(HOST localhost PORT 9600 USER 'xxx' PASSWORD 'xxx' DB 'dict' TABLE 'active_sku_test_local'))
LIFETIME(MIN 0 MAX 0)
LAYOUT(HASHED())总共49个属性去掉24个空的属性,并把String的字段转换成了UInt64,同样的源数据(2kw条),优化后的字典占用内存空间从75GB降到26.5GB,大约降低三分之二。
优化的理论依据
假设字典表有如下字典:
CREATE DICTIONARY dict.test_dict
(
`sku_id` UInt64,
`sku_name` String,
`sku_cat` UInt32
`owner` Nullable(String)
)
PRIMARY KEY item_sku_id
...
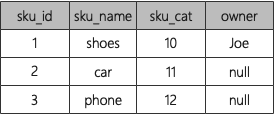
LAYOUT(HASHED())字典数据如下:
以下是Hashed字典在内存中的存储方式,整体上字典没有采用紧凑型的方式存储,而是直接使用了向HashMap、HashSet等数据结构。
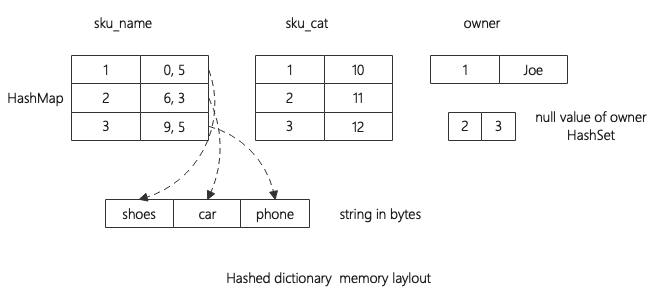
通过字典结构可以分析得出以下优化方法:
1.删除无用属性
每个属性一个HashMap,并且如果属性允许空还会有一个额外的HashSet存储空值对应的key。所以减少一个属性,相当于减少一个HashMap存储,会节省很大的内存空间。
2. String类型改为整数类型
假设属性字段是0-255的取值范围,使用Int16,每个值只需要2个字节,使用String可能需要1-3个字节的数据加上8个字节的偏移量,大约18 bytes左右。可以看到String相比Int16有数倍内存空间的节约。
本作品采用 知识共享署名 4.0 国际许可协议 进行许可, 转载时请注明原文链接。