一、ClickBench性能测试结果
ClickBench是ClickHouse官方性能测试榜单,榜单中43个SQL全部为单表查询,测试重点在单表查询中不同维度组合和基数集大小下的聚合查询的性能。
团队研发了ClickHouse CBO优化器并且将执行架构从Scatter-Gather改造成了Full-MPP的,在10个节点(单节点32C/96G/2T)的测试集群中,跑完一次榜单的执行时间从28.3s降低到22.6s。以下测试基于 这个 commit.
下图显示了ClickBench基准测试中每个查询的时间。测试分为两组:一组启用了新执行框架,另一组没有启用。每组测试运行了三次。
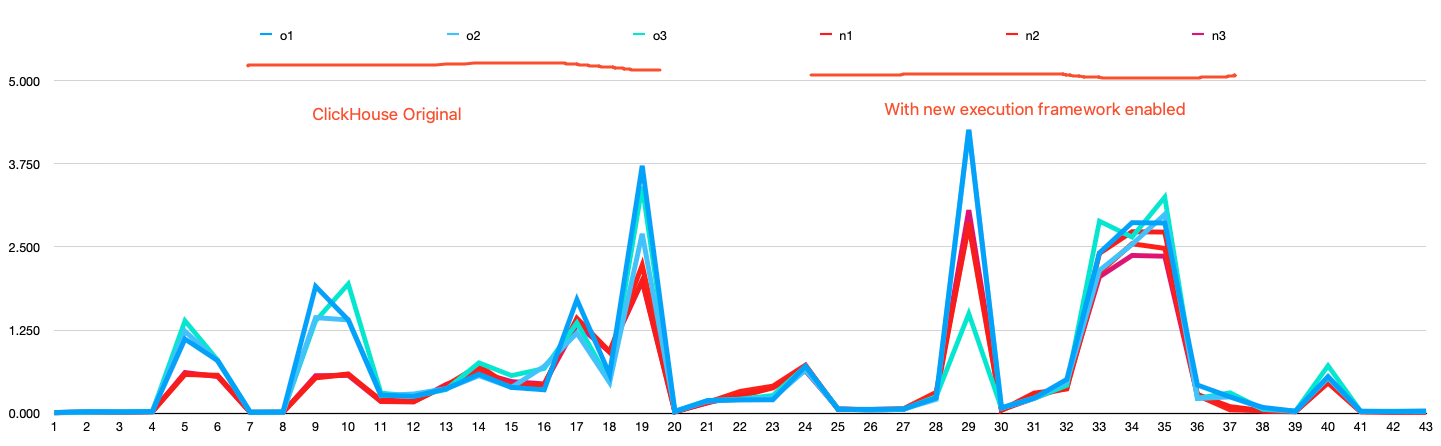
下表显示了在不同并发级别下的测试结果。使用ClickBench基准测试,测试了在1、2、4、8和12个并发级别下完成基准测试的平均时间,时间以秒为单位测量。
| Concurrent levels | 1 | 2 | 4 | 8 | 12 |
| ClickHouse 2.10 | 33 | 19 | 16 | 17 | 13 |
| ClickHouse 2.10 (With the new execution framewrok) | 25 | 14 | 8 | 8 | 9 |
这里对提升较大的查询进行分析,以揭示优化器和MPP执行框架是如何提升查询性能的。请注意后文将称优化器和MPP执行框架为新执行框架。
下面选取两个典型的SQL进行分析:
二、一阶段聚合还是两阶段聚合?
对ClickBench中第5个SQL进行分析开启新执行框架后其查询时间是没有开启的三分之一,SQL如下:
SELECT COUNT(DISTINCT UserID) FROM hits;2.1 执行计划
原生ClickHouse执行计划如下:
┌─explain────────────────────────────────────────────────────────────────────────────┐
1. │ Expression ((Project names + Projection)) │
2. │ MergingAggregated │
3. │ Union │
4. │ Aggregating │
5. │ Expression ((Before GROUP BY + Change column names to column identifiers)) │
6. │ ReadFromMergeTree (default.hits_local) │
7. │ ReadFromRemote (Read from remote replica) │
└────────────────────────────────────────────────────────────────────────────────────┘下图更直观的展示执行计划,请注意为了使图更直观忽略了Expression算子的干扰,其中紫色部分的算子会在所有的节点上执行,白色部分的算子只在初始接受到用户查询的节点上执行。
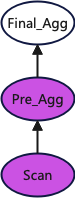
开启新执行框架后的执行计划如下:
┌─explain──────────────────────────────────────────────────────────────────────────┐
1. │ Expression ((Project names + Projection)) │
2. │ Aggregating │
3. │ ExchangeData (distributed by Singleton, sorted by None) │
4. │ Expression ((Before GROUP BY + Change column names to column identifiers)) │
5. │ ReadFromMergeTree (default.hits_local) │
└──────────────────────────────────────────────────────────────────────────────────┘下图更直观的展示执行计划,同上忽略了一些干扰算子,同上紫色部分的算子在所有的节点上执行,白色部分的算子只在初始接受到用户查询的节点上执行。
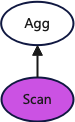
可以看到开启新执行框架的执行计划采用了一阶段的聚合算子,而未开启的执行计划采用了两阶段的聚合算子。
2.2 执行计划分析
简单解释下一阶段聚合和两阶段聚合:
- 一阶段的聚合算子的聚合操作只在初始接收到用户查询的节点进行
- 而两阶段的聚合算子首先在所有节点上做初步的聚合,然后将初步聚合的查询结果发送给初始节点进行二次聚合。
一阶段聚合相比两阶段聚合少了一次数据Pre_Agg的执行但是最终聚合输入的数据量更大。
下图展示了两种聚合方式每个算子的输出的数据量(每个算子输出的数据量也是下游算子需要计算的数据量),其中hits表包含1亿条数据,所以Scan输出1亿条,最终结果是17,630,976所以Final_Agg和Agg输出17,630,976条数据,Pre_Agg输出的数据介与两者之间。
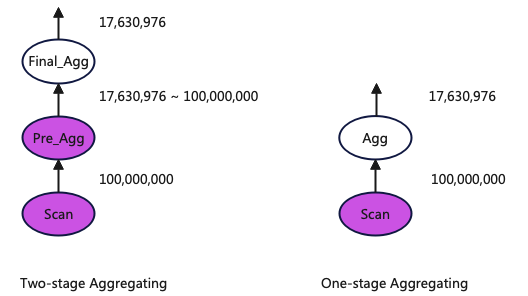
从这个输出数据关系中可以看到UserID的基数集很大,Pre_Agg聚合后数据减少量不明显,所以此时一阶段聚合更优。
三、Shuffle还是Singleton聚合?
对第34个SQL进行分析,开启新执行框架后执行时间3s,开启前需要4s,执行时间降低33%,其SQL如下:
SELECT 1, URL, COUNT(*) AS c FROM hits GROUP BY 1, URL ORDER BY c DESC LIMIT 10;3.1 执行计划
未新执行框架的执行计划
┌─explain──────────────────────────────────────────────────────────────────────────────────┐
1. │ Expression (Project names) │
2. │ Limit (preliminary LIMIT (without OFFSET)) │
3. │ Sorting (Sorting for ORDER BY) │
4. │ Expression ((Before ORDER BY + Projection)) │
5. │ MergingAggregated │
6. │ Union │
7. │ Aggregating │
8. │ Expression ((Before GROUP BY + Change column names to column identifiers)) │
9. │ ReadFromMergeTree (default.hits_local) │
10. │ ReadFromRemote (Read from remote replica) │
└──────────────────────────────────────────────────────────────────────────────────────────┘开启新执行框架的执行计划
┌─explain────────────────────────────────────────────────────────────────────────────────────┐
1. │ Expression (Project names) │
2. │ TopN (Final) │
3. │ ExchangeData (distributed by Singleton, sorted by Stream(count())) │
4. │ TopN (Preliminary) │
5. │ Expression ((Before ORDER BY + Projection)) │
6. │ MergingAggregated │
7. │ ExchangeData (distributed by Hashed, sorted by None) │
8. │ Aggregating │
9. │ Expression ((Before GROUP BY + Change column names to column identifiers)) │
10. │ ReadFromMergeTree (default.hits_local) │
└────────────────────────────────────────────────────────────────────────────────────────────┘3.2 执行计划分析
可以看到两个执行计划都是两阶段的,区别是新执行框架后采用了shuffle的聚合方式,而没有开启新执行框架采用了singleton的聚合方式。
首先简单解释下singleton和shuffle聚合,它们都是两阶段聚合方式,区别是:
- singleton聚合的第二阶段Final_Agg在一个节点执行,所以下游的Pre_Agg需要将数据发送到一个节点
- shuffle聚合的第二阶段Final_Agg在所有节点执行,所以下游的Pre_Agg需要将数据根据聚合的keys发送到对应的节点,这些节点是集群中所有的节点
shuffle和singleton聚和的优缺点:
- singleton聚合:优点是少了一次数据传输,缺点上Final_Agg只能由一个节点执行,同时后续的TopN只能在一个节点上执行。
- shuffle聚合:与singleton相对应,优点是Final_Agg连同Pre_TopN可以在多个节点上执行,缺点是多了一次数据传输。
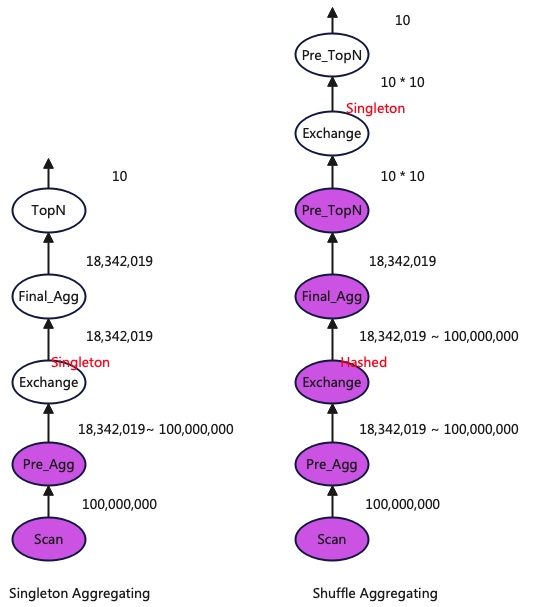
上图展示了两个执行计划对比图,途中包含了每个算子输出的数据量。其中Final_Agg输出的数据量由去除掉limit和orderby的sql得到。可以得出结论当Pre_Agg输出的数据量比较大的时候采用Shuffle聚合方式更优。
3.3 原生ClickHouse局限性
原生ClickHouse不支持Shuffle聚合方式。
3.4 进一步分析
采用Shuffle集合方式后查询的峰值内存使用从3GB降低到1.76GB。
# Singleton Aggregating:
10 rows in set. Elapsed: 4.053 sec. Processed 100.00 million rows, 9.94 GB (24.67 million rows/s., 2.45 GB/s.)
Peak memory usage: 2.52 GiB.
# Shuffle Aggregating:
10 rows in set. Elapsed: 2.751 sec. Processed 100.00 million rows, 9.94 GB (36.35 million rows/s., 3.61 GB/s.)
Peak memory usage: 1.56 GiB.四、更多聚合执行方式
其实还有以下两种聚合方式暂时没有实现:
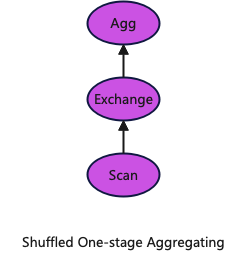
1.一阶段shuffle聚合
Agg下游的算子直接将数据按照聚合keys进行shuffle,分发给集群中所有的节点,然后进行聚合。
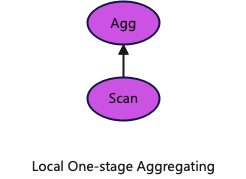
2.本地一阶段聚合
如果表中的数据在集群中是按照查询的聚合keys进行散列的,那么每个节点可以直接在本地进行聚合生成部分最终结果。在执行计划总可以直接省略一阶段shuffle聚合中的Exchange算子。
五、小结
本文揭示了新执行框架在单表聚合查询场景中性能提升的秘密,:新执行框架中新增了两种聚合执行算子的方式,并且根据统计信息动态的选择更优的执行方式。:
- 一阶段的聚合
- shuffle的两阶段聚合
在ClickBench榜单中大多数有性能提升的查询是因为采用了shuffle的两阶段聚合方式,所以在ClickBench测试集中的大多数场景中shuffle的两阶段聚合方式相比ClickHouse原生的Singleton两阶段聚合方式更优一些。
经过测试发现,Doris 与开启新执行框架的 ClickHouse 的执行计划相同,但是 Doris 的表现更优。经过分析发现,可能是因为 Doris 中的 Exchang 算子在发送和接收端都是异步的,然而在新执行框架的 ClickHouse 中却是同步的,这一点待POC验证。
本作品采用 知识共享署名 4.0 国际许可协议 进行许可, 转载时请注明原文链接。