Authors of this article: JackyWoo, Zhuoyu Li
RaftKeeper is a high-performance distributed consensus service that is fully compatible with Zookeeper but offers superior performance. For more information about RaftKeeper, refer to its GitHub page. We have extensively applied it in ClickHouse scenarios to address the performance bottlenecks of ZooKeeper. Additionally, RaftKeeper can be used with other big data components such as HBase.
As an important release following v2.0.0, v2.1.0 introduces a series of new features, including asynchronous snapshot creation. The highlight of this version is its performance optimization: write request performance has improved by 11%, and mixed read-write scenarios have seen a significant 118% improvement. This article will delve into the improvements and optimizations of the new version from an engineering perspective.
1. Performance Optimization Effects
In the performance tests, we used the raftkeeper-bench tool. The test environment consisted of a cluster with three nodes, each configured with a 16-core CPU, 32GB of memory, and 100GB of storage space. The test subjects included RaftKeeper v2.1.0, RaftKeeper v2.0.4, and ZooKeeper 3.7.1, all using default configurations.
The tests were divided into two groups.
The first group tested the performance of pure create operations, where the size of the value for each create operation was 100 bytes. The results showed that RaftKeeper v2.1.0 had an 11% performance improvement compared to v2.0.4 and a 143% performance improvement compared to ZooKeeper.
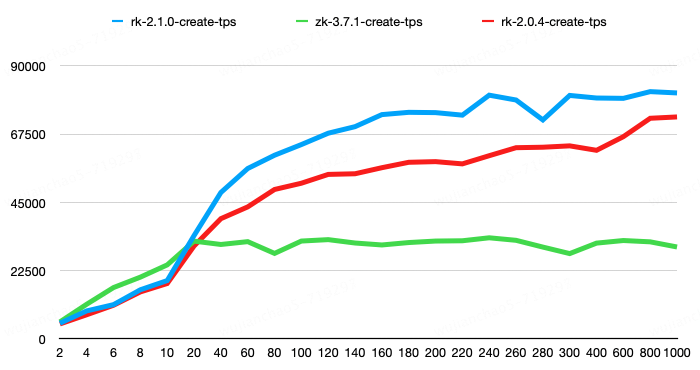
The second group had a request mix consisting of 1% create, 8% set, 45% get, 45% list, and 1% delete operations. In this scenario, the list request results included 100 child nodes, with each child node having a size of 50 bytes. The get, set, and create requests had node values of 100 bytes each. The results showed that RaftKeeper v2.1.0 achieved a 118% performance improvement compared to v2.0.4 and a 198% performance improvement compared to ZooKeeper.
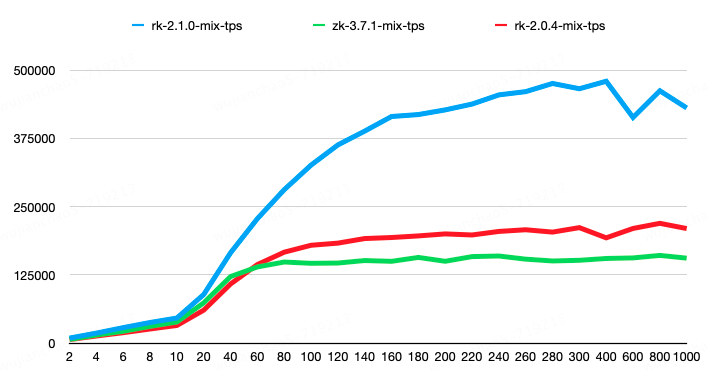
In the tests, the RaftKeeper v2.1.0 version outperformed v2.0.4 in both the average response time (avgRT) and the 99th percentile response time (TP99) metrics. For detailed performance metrics, please refer to the test report.
2. Performance Optimization
Next, from an engineering perspective, let’s introduce some of the optimization points in v2.1.0.
1. Parallelized Response Serialization
RaftKeeper is widely used in ClickHouse. The following flame graph shows a large-scale RaftKeeper cluster. From the flame graph, we can see that the ResponseThread consumes a significant amount of CPU time, with approximately one-third of the time spent on serializing responses.
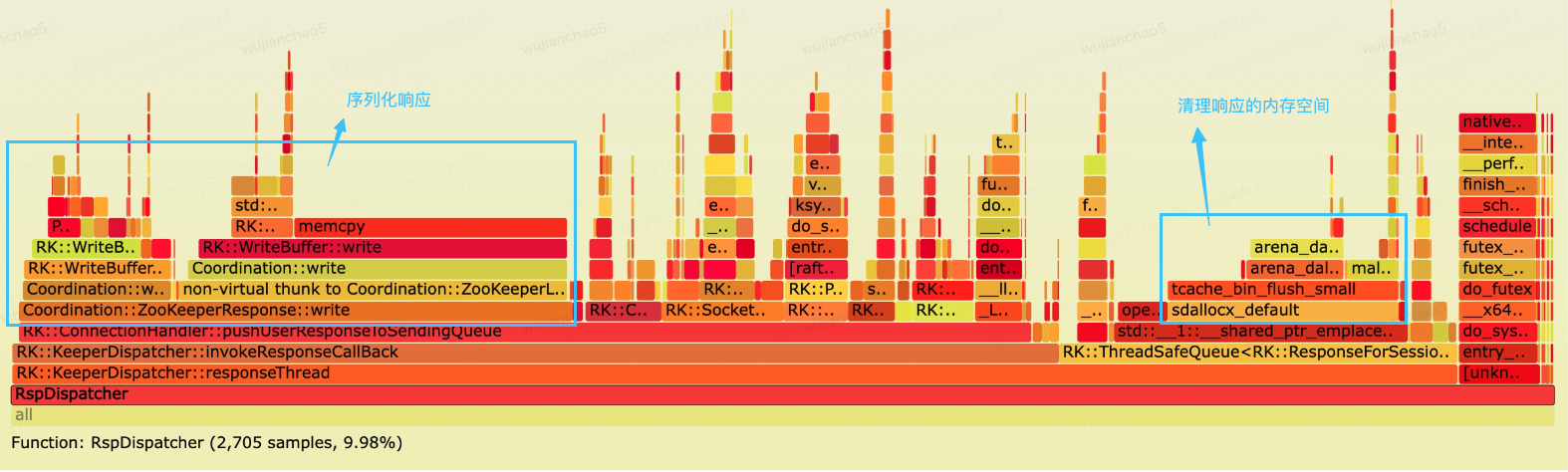
The ResponseThread is responsible for serializing responses and forwarding them to the IO thread. It is a single-threaded process, and serial execution of serialization increases latency. We can delegate the serialization of responses to the IO thread, allowing for concurrent execution to improve throughput.
Additionally, we can see that the sdallocx_default function consumes a significant amount of CPU time. This function is used by jemalloc to free memory. While the time consumption of this function itself is not an issue, performing this operation in a mutex-based synchronized queue increases lock time.
/// The responses_queue is a mutex-based synchronized queue. Releasing response_for_session in the tryPop method increases the lock time.
responses_queue.tryPop(response_for_session, std::min(max_wait, static_cast<UInt64>(1000)))The solution is to release the memory space of response_for_session before the tryPop method is called.
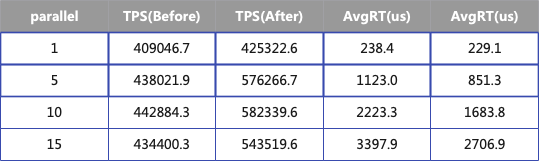
The table below shows the performance metrics before and after optimization. The test consists of four groups, each using a different level of concurrency, with a response size of 50 bytes. When the concurrency level is 10, TPS increases by 31%, and AvgRT decreases by 32%.
2. Optimizing List Requests
In the same RaftKeeper cluster, flame graphs revealed that processing List requests consumed nearly all CPU time slices of the request-processor thread. In RaftKeeper’s execution chain, the request-processor is responsible for handling user requests. Since it is a single-threaded component, it can easily become a bottleneck.
The flame graphs identified two bottlenecks:
- Allocating memory space for strings;
- Inserting into vectors.
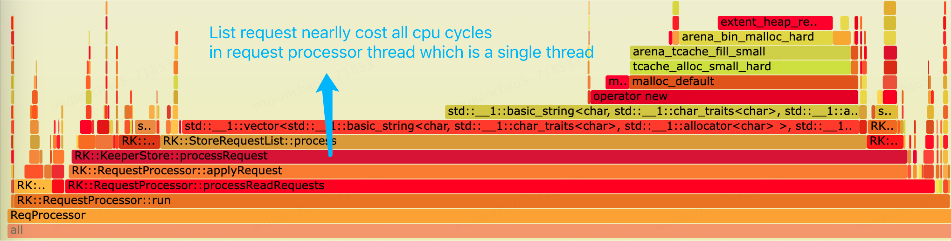
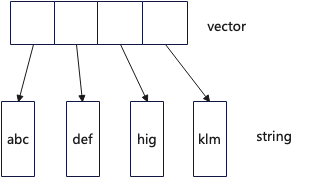
List requests return a std::vector<string> dynamic array. The memory layout is illustrated in the diagram below. Each element is a string, and each string requires a block of dynamic memory to store its data. Therefore, when there are many strings, a large number of dynamic memory allocations are needed.
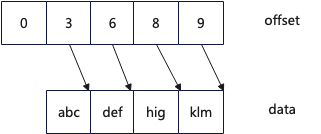
An intuitive optimization approach is to design a compact strings structure where the data is stored in a compact manner. In the design below, two contiguous memory spaces are used: one for storing the data and one for storing the offsets. For specific implementation details, refer to the CompactStrings implementation.
After optimization, the CPU usage for handling List requests, as seen from the flame graph, decreased from 5.46% to 3.37%. In benchmark testing for List requests, TPS increased from 458,000 requests per second to 619,000 requests per second, and the TP99 latency also improved.
Before:
read requests 14826483, write requests 0, Read RPS: 458433, Read MiB/s: 2441.74, TP99 1.515 msec
After:
read requests 14172371, write requests 0, Read RPS: 619388, Read MiB/s: 3156.67, TP99 0.381 msec.3. Optimizing Redundant System Calls
System calls cause context switches between user mode and kernel mode, which often incur significant overhead. We profiled RaftKeeper using bpftrace to identify and optimize these costly system calls.
BPFTRACE_MAX_PROBES=1024 bpftrace -p 4179376 -e '
tracepoint:syscalls:sys_enter_* { @start[tid] = nsecs; }
tracepoint:syscalls:sys_exit_* /@start[tid]/ {
@time[probe] = sum(nsecs - @start[tid]);
delete(@start[tid]);
@cc[probe] = sum(1);
}
interval:s:10{ exit(); }
'We discovered that a significant amount of overhead was caused by numerous getsockname and getsockopt system calls.
Execution count:
@cc[tracepoint:syscalls:sys_exit_getsockname]: 2878146
@cc[tracepoint:syscalls:sys_exit_getsockopt]: 2821796
Execution time (ns):
@time[tracepoint:syscalls:sys_exit_getsockopt]: 3161677518
@time[tracepoint:syscalls:sys_exit_getsockname]: 2647505715These system calls should not have been present. Upon investigation, we found that they were erroneously invoked during logging.
const auto socket_name = sock.isStream() ? sock.address().toString() : sock.peerAddress().toString();
LOG_TRACE(log, "Dispatch event {} for {} ", notification.name(), socket_name);4. Thread Pool Optimization
The following diagram is a benchmark (with a 4:6 read-to-write ratio) flame graph of RaftKeeper. Performance bottleneck analysis revealed that the request-processor threads spend most of their CPU time (over 60%) on condition variable wait calls.
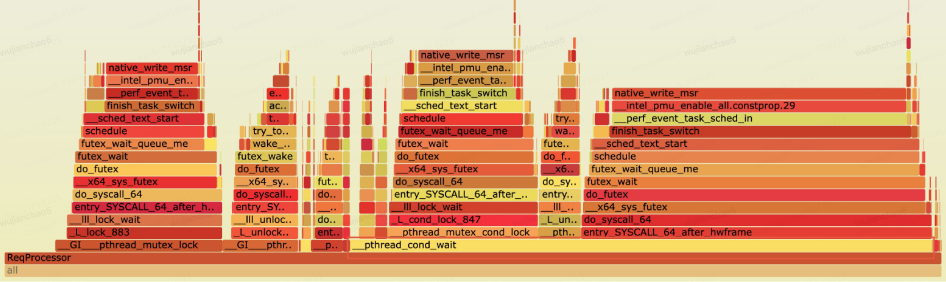
In RaftKeeper’s main execution path, the request-processor threads are responsible for handling user requests. The primary process can be abstracted as follows:
- For write requests, they are processed by a single thread.
- For read requests, they are handled concurrently through a thread pool. The request-processor thread then calls
request_thread->wait()to block and wait for all read requests to complete.
/// 1. process read-request by a thread pool
for (RunnerId runner_id = 0; runner_id < runner_count; runner_id++)
{
request_thread->trySchedule(
[this, runner_id]
{
moveRequestToPendingQueue(runner_id);
processReadRequests(runner_id);
});
}
/// 2. wait read request processing
request_thread->wait();
/// 3. process write-request in single thread
processCommittedRequest(committed_request_size);By adding monitoring metrics to separately track the execution times of read and write requests, it was found that, with nearly equal numbers of read and write requests, the processing delay for read requests was three times that of write requests.
Given that each request’s processing time is very short, it can be inferred that the task scheduling time of the thread pool is significant, leading to performance degradation. The solution was to remove the thread pool and handle read requests with a single thread. The benchmark results before and after optimization showed a 13% increase in TPS (Transactions Per Second).
Before:
thread_size,tps,avgRT(microsecond),TP90(microsecond),TP99(microsecond),TP999(microsecond),failRate
200,84416,2407.0,3800.0,4500.0,8300.0,0.0
After:
thread_size,tps,avgRT(microsecond),TP90(microsecond),TP99(microsecond),TP999(microsecond),failRate
200,108950,1846.0,3100.0,4000.0,5600.0,0.03. Snapshot Optimization
1. Asynchronous Snapshot Creation
In the entire request processing chain of RaftKeeper, creating a snapshot is handled in the main execution path. When the data volume is large, this can cause prolonged blocking of user requests, leading to request timeouts, leader switches, and service unavailability. In our online scenarios, creating a snapshot for 60 million data entries can take 180 seconds.
To address this issue, the new version supports asynchronous snapshots. When a snapshot needs to be created, the entire DataTree is first copied. This step is handled in the main thread. Then, the copied DataTree is serialized to disk in the background.
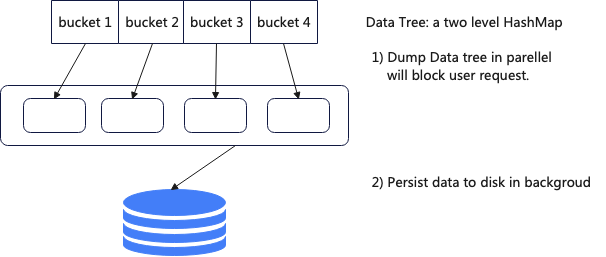
Using this approach, the blocking time for creating a snapshot of 60 million data entries has been reduced from 180 seconds to 4.5 seconds. However, this solution also has some negative effects, such as consuming more than 50% additional memory.
To further reduce the blocking time for users, the copying of the DataTree has been further optimized. The DataTree copy is actually a compute-intensive task, so vectorization can be employed. Additionally, since it involves traversing a hashmap, prefetching can be appropriately utilized.
inline void memcopy(char * __restrict dst, const char * __restrict src, size_t n)
{
auto aligned_n = n / 16 * 16;
auto left = n - aligned_n;
while (aligned_n > 0)
{
_mm_storeu_si128(reinterpret_cast<__m128i *>(dst), _mm_loadu_si128(reinterpret_cast<const __m128i *>(src)));
dst += 16;
src += 16;
aligned_n -= 16;
__asm__ __volatile__("" : : : "memory");
}
::memcpy(dst, src, left);
}The copy function is based on the SSE instruction set, and after optimization, the DataTree copy time has been reduced from 4.5 seconds to 3.5 seconds.
2. Snapshot Loading Speed Optimization
In older versions of RaftKeeper, the snapshot loading speed after starting the service was relatively slow. An online RaftKeeper instance used as ClickHouse metadata storage with 6 million data entries took 180 seconds to load the snapshot on an NVMe disk server, resulting in a slow service startup.
The snapshot loading process is mainly divided into two steps. The first step is reading data from the disk and deserializing it into nodes. The second step is traversing the DataTree and constructing parent-child relationships. The first step is parallelized, while the second step is single-threaded.
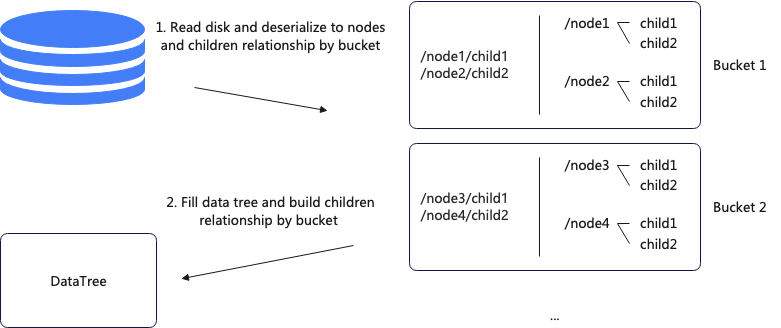
Since the second step is executed in a single-threaded manner, it can be modified to a parallel approach. The basis for parallelization is that the DataTree is a two-level HashMap structure. After the modification, each thread is responsible for a fixed bucket, thus avoiding concurrency issues. The specific process involves first reading data from the disk and storing nodes and parent-child relationships according to the granularity of the buckets, then populating the DataTree and constructing parent-child relationships.
After optimization, the snapshot loading time was reduced from 180 seconds to 99 seconds. Further optimizations, including lock optimization, snapshot format optimization, and reducing data copying, brought the time down to 22 seconds.
4. Online Results
We selected an online ClickHouse cluster with a high request volume to ZooKeeper. According to the monitoring metrics on the ClickHouse side, the QPS was approximately 170,000/s, with the majority being List requests. We then sequentially upgraded it from ZooKeeper to RaftKeeper v2.0.4 and v2.1.0, and observed the monitoring metrics.
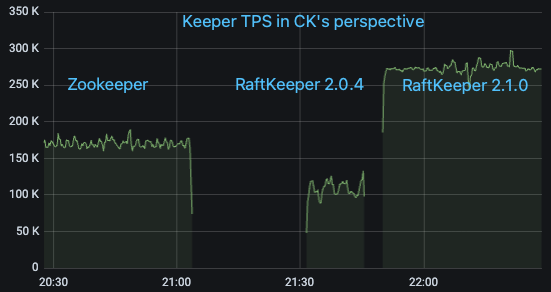
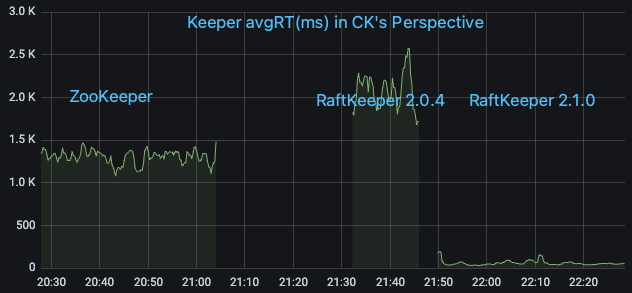
It can be seen that RaftKeeper v2.0.4’s performance was not as good as ZooKeeper’s (mainly because the majority of requests in this scenario were list requests, and v2.0.4 had poor performance for list requests). However, RaftKeeper v2.1.0 showed a significant improvement.
5. At Last
In large-scale ClickHouse deployments, we found that RaftKeeper significantly improved ClickHouse’s query throughput. If you encounter similar issues, consider using RaftKeeper. For more information about RaftKeeper v2.1.0, please refer to the Release Notes. We welcome you to try it out and contribute code. If you have any questions, please contact us through the community.
RaftKeeper in Github:https://github.com/JDRaftKeeper/RaftKeeper
V2.1.0 Release Note:https://github.com/JDRaftKeeper/RaftKeeper/releases/tag/v2.1.0
raftkeeper-bench:https://github.com/JDRaftKeeper/raftkeeper-bench
This work is licensed under a Creative Commons Attribution 4.0 International License. When redistributing, please include the original link.