需求介绍
这次集群迁移的大背景是所有的业务与服务需要从一个机房迁移到同城的另外一个机房,因为需要灰度观察所以迁移可能会持续一个月,迁移期间需要保证业务正常访问。迁移后原机房的服务将下线。
简单介绍下我们的Redis集群,集群以Redis-cluster为基础,采用一主一从的架构,集群总共有节点800多个。数据量大概几十亿,每天高峰写QPS200w。
整体计划
对于Redis集群的整体迁移计划分为三个阶段:
一 数据准备
数据准备阶段需要达成的目标是同步两个机房的数据,并且需要在整个切流期间持续同步,这是重点与难点。为此采用的方案是在源机房的每个Redis上部署一个Agent,它收集集群的写数据事件,并同步到目的机房,然后源机房的Redis进行RDB,并将其导入到目的机房的Redis集群中。
该方案是一种单向同步的过程,写事件只能从源机房流向到目的机房。这种方案要求在目的机房的业务系统的写操作,只能写源机房,写更新通过Agent同步到目的机房。
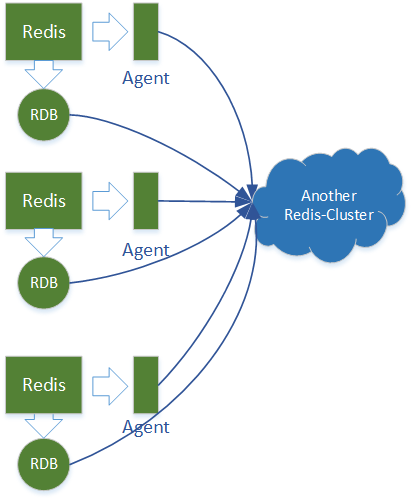
上图描述了机房间数据同步的流程,更多关于数据同步见下文Agent设计小节,本文约定,绿色图标代表源机房的服务,蓝色图标代表目的机房的服务,下文中的图片也都遵循这个约定。
与这种方案相对应的还有一种双向同步方案,两个机房的Redis上都部署Agent,对于两个机房的业务系统的写操作,都通过Agent同步到对方。但是这种方案是行不通的,因为Agent设计依赖Redis的键空间订阅机制,它不能区分写操作的来源,所以同步到对方的写操作,还会被同步过来,导致踢皮球似的无限循环。
二 流量切分
Redis集群数据同步完成之后,业务系统就可以对流量进行切分了。由于数据增量同步是单向的,从源机房到目的机房。所以对于目的机房的业务系统产生的数据也需要写入到源机房的Redis集群中去。为此我们采用的方案是,对于源机房的业务系统读写源机房的Redis集群,对于目的机房的业务系统写操作在源机房的Redis集群,读操作在目的机房的Redis集群。采取这样方案的理由是每一次业务请求,会写一次读多次Redis,而这种方案对线上服务的影响是较小的。
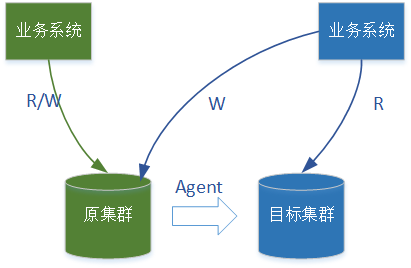
三 切分完成
等业务系统全部切换到目的机房之后,此时切分完成,业务系统对Redis的读写都在目的集群,待运行稳定之后源机房的Redis集群与Agent可以做下线处理。
数据一致性
我们再一次明确现行的方案,先给Redis节点添加Agent,以订阅增量更新,在备份节点全量数据,然后导入到目的机房的集群中,导入的时候保证如果key在目的集群已经存在则丢弃的原则。在分析方案可行性之前我们先明确一个前提,我们给Redis收窄了接口,只有String类型的get与set操作,没有delete等其它操作。

上图展示了任意一个key在不同时间节点上发生的更新操作的场景,因为如果任意一个key都是同步的那么整个集群就是同步的,所以下文讨论一个key的场景。其中T1\T2\T3分别代表添加Agent,RDB该key与导入该key的时间点。U1\U2\U3分别代表该key在不同时间段的更新(set)操作。
对于源集群一定是U3覆盖U2,U2覆盖U1,所以保证目的集群也是这种覆盖规则就能保证集群之间数据的一致性。对于U1因为更新会被同步到目的集群中,所以T1-T2时间段内对key的更新是同步的。同理对于U2更新同样会同步,但是注意这时候RDB中已经保存了key的U1版本,因为导入数据的时候遵守存在则丢弃的原则,所以RDB中的U1版本不会被导入到目的集群中,保证了U2覆盖U1的原则。同理U3也会同步到目的集群,覆盖U2。所以整个流程两个集群的数据是同步的。
但是这种同步对于目的集群中的业务系统来说不是严格的读写同步。因为它写数据到源集群请求就返回了,此时写更新还没有同步到目的集群,如果此时去读该条数据,就会读到脏数据。但是在我们的场景中业务方没有这种需求,所以该方案是可行的。
Agent设计
Agent主要作用是订阅Redis中特定key的写事件并发送到目的集群中。它主要依赖Redis的键空间订阅机制。Redis定义了一套灵活的消息发布订阅机制。Redis中产生的消息,首先在服务端进行一次过滤,服务端过滤后的消息,每个客户端都可能会收到。每个客户端还可以对消息进行进一步的过滤,来获取自己感兴趣的消息。所以在整个发布订阅处理链条中,最终每个客户端所订阅到的消息是经过两次过滤的结果。
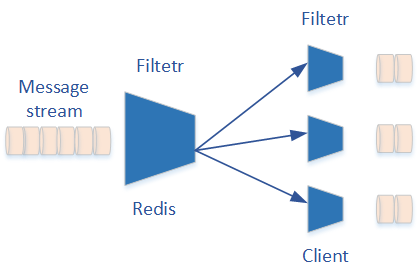
首先看消息产生环节,对于每一个写操作,Redis会产生两个消息,我们以set操作为例,set操作触发的的两个消息与如下两个PUBLISH命令相同:
PUBLISH __keyspace@0__:mykey set
PUBLISH __keyevent@0__:set mykey上边的两个PUBLISH命令第一个参数代表channel,第二个参数代表message,很容易观察到两个命令的channel与message是互相颠倒的,逻辑上这两个消息的意义是有着极大区别的。其中第一个被称作是“Key-space-notification”,它关注key本身,会订阅到mykey的所有操作。第二个被称作是“Key-event-notification”,它关注操作本身,会订阅到所有key的set操作。
接下来看第一次过滤,第一次过滤发生在服务端,默认情况下服务端对所有的消息全部过滤,也就是全部丢掉,所以我们需要设置过滤规则来保留希望留下的消息。因为在我们的集群中只有简单字符串类型的数据,写操作只有set,并没有删除操作,所以过滤规则如下:
redis-cli -p $port config set notify-keyspace-events '$sK'其中‘$‘代表字符串类型的命令,‘s’代表set命令,‘K’代表“Key-space-notification”,它们组合起来表示保留所有字符串类型key的set命令产生的消息。在Redis内部以上命令会被翻译成“PUBLISH __keyspace@0__:* set”,其中星号是通配符表示所有的key。
最后看第二次过滤,第二次过滤发生在客户端,这样每个客户端就能在服务端第一次过滤的基础上订阅到自己感兴趣的内容。因为我们最终需要订阅到的key都有固定的前缀,所以最终客户端订阅命令有点类似如下的形式:
redis-cli -p $port psubscribe __keyspace@0__:prefix1*
redis-cli -p $port psubscribe __keyspace@0__:prefix2*
redis-cli -p $port psubscribe __keyspace@0__:prefix3*
...通过以上的一些设置,我们就订阅到关注的key的写事件了,接下来我们以工程的角度考虑一些事情。
首先键空间订阅机制并不是一个可靠的消息订阅机制。因为Reids会把符合条件的事件放到每个连接对应的缓冲区中,当连接断开的时候该缓冲区会被销毁,其中的消息会被丢去,所以需要做好异常与报警方面的工作。如果发现丢失的消息较多,可以考虑重新全量导入该节点的数据,重新导入的时候,不能再遵循存在则丢弃的原则,应该遵循存在则删除,再次导入的原则。
其次发布订阅缓冲区是一个典型的生产消费模型,当消费的速度慢于生产的速度的时候,很可能会导致缓冲区溢出,Redis对于pubsub缓冲区溢出的处理策略是,清空缓冲区并且重置连接。为了避免消息丢失,我们需要保证消费的速度大于生产的速度。
在我们的场景中Agent中使用Jedis作为Redis的客户端,Jedis使用BIO网络模型,并且在订阅接口中没有多线程机制。考虑到机房之间7ms的网络RTT,如果数据处理的逻辑不做多线程处理每秒最多处理1000/7=142个更新事件,这里解释一下,Redis处理的速度是极小的,大概几十微妙,所以这里只取7ms的RTT时间。
单个线程一秒只能处理142个消息,所以Agent需要设计为多线程的,那么到底需要多少个线程?如果每个节点每天的写请求数量为2千万,那么一天的平均QPS为231,考虑到高峰时段平均QPS为500。所需要的线程数量至少为:==7*500(高峰时段QPS) / 1000 = 3.5个==,考虑到突发高峰可以在设置大一些,比如7个,具体多少视实际情况而定。我们这次是按照高峰QPS所需要线程数量的double设置的。
同时也可以适当调整缓冲区的大小,来增加消峰的能力,可以通过如下命令来调整Redis pubsub缓冲区的大小:
redis-cli -p $port config set client-output-buffer-limit "normal 0 0 0 slave 536870912 134217728 60 pubsub 33554432 8388608 60"结果验证
当全量数据同步完成之后我们的预期是两个机房的数据是完全一致的,但是完全一致,开玩笑怎么可能,所以我们需要验证数据的偏差是多少。验证的指标有三个:(1)同一个key的value是否相同(2)同一个key的TTL(因为我们的数据都是有TTL的)的偏差是否较大,这里以10ms为界(3)两个机房的数据量偏差有多大。
前两点的验证方案采用随机取样的方式,比如每次取样10w个key,然后对比结果。经过三次校验的结果是有十万分之一的数据偏差,与业务沟通差异是能够接受的。第三点数据量的验证很简单,只需要取出两个集群的数据量对比即可。
至此数据同步工作已经完成,接下来只需要日常运维,保证Agent稳定,等到最终业务完全切分完毕,在去掉Agent即可。
思考与感悟
在全量同步的问题上,计划的方案是在从节点上进行RDB,然后将RDB文件传输到目的机房,在之后进行导入。采用这样的方案的考量要点主要是:(1)在从节点上进行RDB对线上服务的影响最小(2)将RDB文件传输到目的机房进行导入,降低了机房之间数据传输的压力。
但是在实际的操作中,之前计划的方案都没有没遵从,实际的方案是在主节点上进行RDB,然后在主节点所在的上进行数据导入工作。采用这样的方案最根本的原因是在不影响线上服务的基础上实施起来简单。
可能很多人都希望给问题设计一个完美的方案,但是完美的方案带来的可能带来更多的复杂性与操作的危险性,在考虑到人员的时间成本,在满足基本要求的基础上具体实施方案可以看起来不那么完美。
本作品采用 知识共享署名 4.0 国际许可协议 进行许可, 转载时请注明原文链接。