本文分析ORC中字典的实现,图1展示了本文中用到的列值序列。

When inserting
1 Building a dictionary by putting values into an in-memory array and encoding it with sequence order.
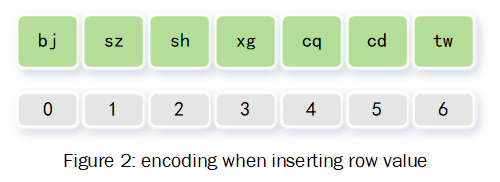
2 Store row values with encoding number(in-memory)
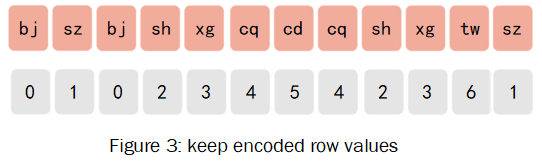
3 keep an index of distinct values with red-black-tree.
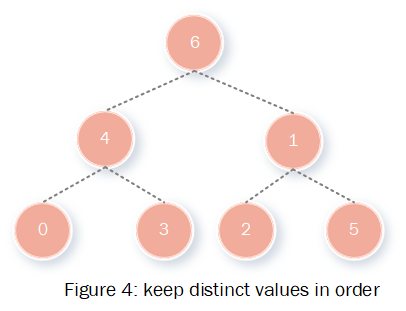
红黑树的节点是编码过的列值,但是排序时使用真实的列值排序,这样索引保证了列值是按真实值排序的。
当插入新数据的时候,需要判断字典中数据是否存在该数据,由于索引的存在查询复杂度是O(ln2)的,大大减小了查询时间,这是红黑树索引设计存在的意义。
2 When flushing column
分析:当数据插入完毕,flush数据的时候,有两项操作;第一按字典顺序重新编码;第二用新的字典对数据进行编码。这样做的目的是保证flush到磁盘的字典是按照真实值有序的,从而保证查询的高效。
1 Re-encoding data
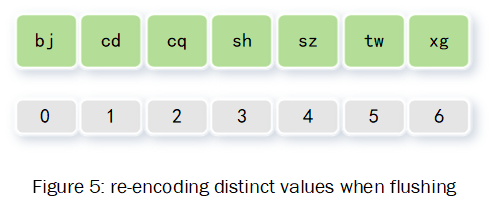
2 Building a mapping between two encoding(in-memory)

3 when flush rows into disk, use new encoding number
4 column layout

3 When reading
字典使用的时候就比较简单了,我们先将问题抽象出来:用户发出scan的命令,此时ORC需要将列值(数字)Translate成列值,其实就是已知下标,然后读取数组的问题。
将关注点放到如何使用内存上,其实ORC的内存使用策略是将字典一次性读入内存。为什么能直接全量读入内存呢?首先字典的作用范围是一个Stripe,每个Stripe在构建的时候已经做过一次内存大小的限制了,所以全量读取一般也不会发生OOM。
本作品采用 知识共享署名 4.0 国际许可协议 进行许可, 转载时请注明原文链接。