ClickHouse是一款优秀的OLAP产品,其在行业内引领了向量化执行引擎的潮流,同时在很多方面尤其是底层数据结构算法优化和功能丰富度方面非常优秀,但是对于优化器方面是短板。为此团队研发了ClickHouse CBO优化器,旨在进一步提升ClickHouse的性能。
一、优化效果
我们用来测试的榜单选择了ClickHouse的ClickBench,数据集1亿,测试环境5个节点的ClickHouse集群,集群单副本,单节点规格:32C/128G/1TB(NVMe) 。
Benchmark方式是在开启或者关闭CBO优化器的情况下榜单中的查询各跑3次。Benchmark结果如下:
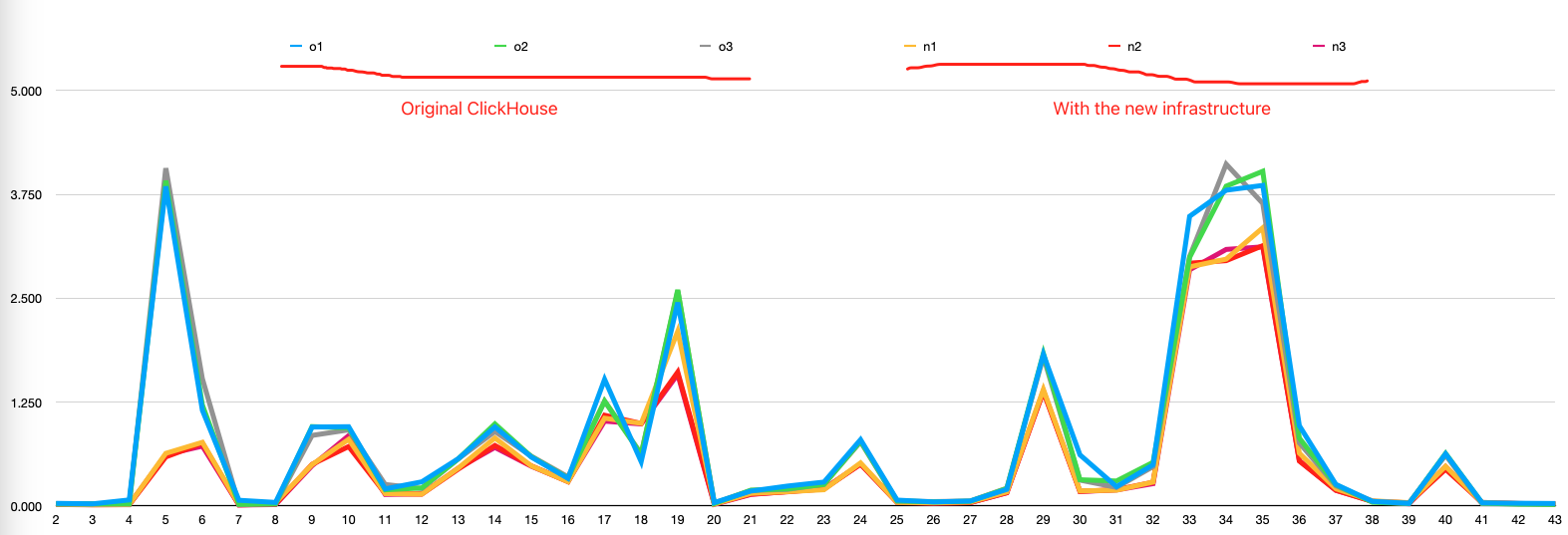
在开启CBO优化器后部分查询有明显提升,43个SQL的总查询时间从32s降低到22s。
PS:ClickBench榜单是只有单表聚合的查询,查询比较简单,在多表情况下预计CBO优化器对性能提升更明显。
二、为什么需要优化器?
本着一例顶千言的原则,我们使用两个query(例子)来说明
query_1
select a,b,c from t1 inner join t2 on t1.id=t2.id where t1.d='xx'假设一个100节点的集群,两个表t1和t2分别有10亿行和100行数据,那么query_1的执行计划如下:
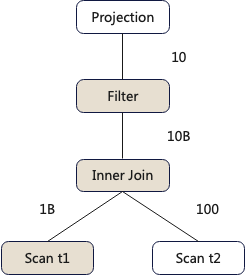
PS:图中方块代表算子,线中的数字代表下方的算子输出的数据,比如Inner Join后输出100亿行数据。
如果我们希望提高查询性能,可以如何对其进行优化?
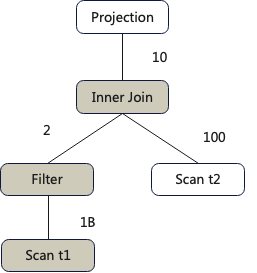
1.基于规则的等价变换
我们可以将Filter算子下推到Inner-join下方,提前过滤这样Inner Join需要计算的数据量从之前的10亿+100变成了2+100,
2.选择合适的算法
query_1中的Inner-join是最消耗性能的算子,所以对其进行优化对整个查询的性能有重要影响。
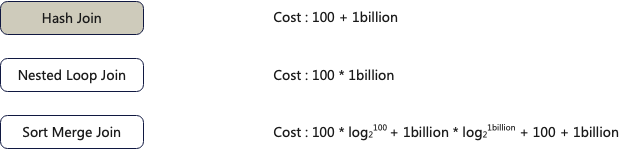
可以看到不同的算法数据计算的代价有数量级的差异,这里我们选择了Hash Join算法
3.算子的数据分发属性
数据分发属性指的是下层算子的算法如何分发给上次算子,这种优化方式主要在分布式数据库中使用,假设query_1的集群共有100个节点,对于Inner-join下方的算子数据有2中分发方式
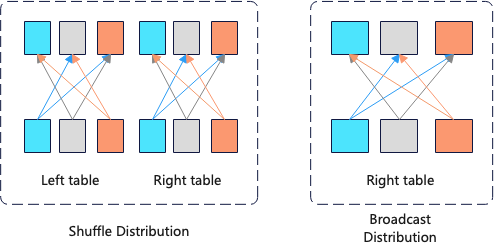
对于shuffle分发方式需要网络传输10亿行,对于broadcast方式需要网络传输100*100行,所以这里boradcast数据分发方式更优。
query_2
在看另外一个例子,如何进行优化?
select a, sum(b) from t1 group by a下图中左侧是查询计划,右侧是优化后的执行计划
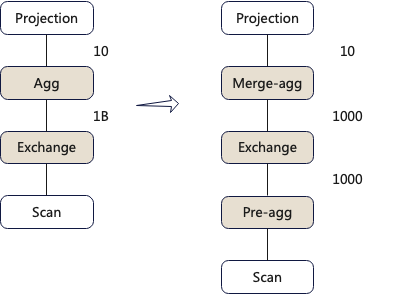
左右两个执行计划的差异是聚合算子的算法不同。左侧执行计划使用一阶段聚合方式,scan后的数据直接发送给一个节点进行聚合。右侧优化后的执行计划使用了两阶段的聚合方式,每个节点首先进行初步聚合,然后将初步聚合后的结果发给一个节点进行二次聚合。
两种不同算法的Exchange算子进行网络传输的数据量分别是10亿和1000,显然右边的算法更优。
通过以上2个例子我们可以看到,SQL作为一种编程语言,它只告诉了我们要做什么,而没有告诉如何做,并且不同的做法对于性能的影响极其大,所以我们需要优化器来选择合适的执行计划。
三、为什么需要CBO优化器?
在以上两个例子中给出了一些列优化措施,但这些优化是站在上帝视角得出来的,实际上我们并不知道每个算子输出的数据量,也不清楚每个算子计算的代价,当数据特性不一样的时候选择,如何选择不同的执行计划呢?
1.假设query_1中Inner-join的输入是有序,选择哪个算法?
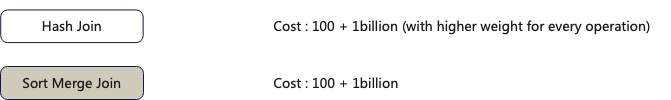
根据两种算法不同的计算代价,此时选择Sort-Merge算法更合适。
2.假设query_1中Inner-join的数据集都很大,如何进行数据分布?
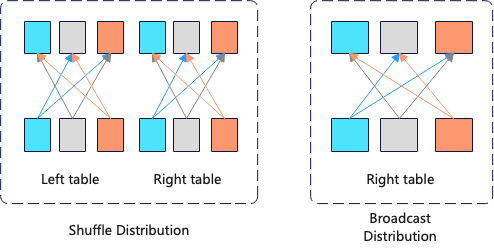
比如左右表的数据量都是10亿,那么shuffle的数据分发方式需要网络传输数据大概20亿,而此时broadcast方式需要网络传输数据大概100节点 *1B = 1000亿。此时shuffle的数据分发方式更合适。
3.假设query_2中数据的基数集特别大,如何选择聚合方式?
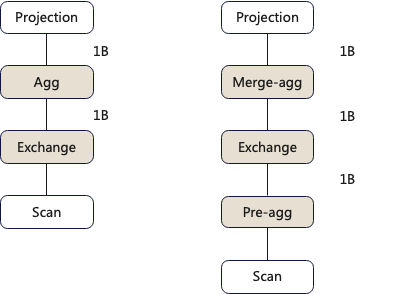
比如数据的基数集是10亿,对于左边执行计划的一阶段的聚合方式,Exchange的网络传出开销是10亿,聚合开销是10亿;对于右边执行计划的二阶段聚合方式,Exchange的网络传出开销是10亿,聚合开销是20亿,显然此时选择左边一阶段的执行计划更合适。
总而言之,对于有些优化,其效果严重依赖数据特性(数据大小、基数集、排序特性、数据分布),所以需要CBO这种基于数据特性的优化方式。
四、如何使用
目前我们提了一个PR到社区,有兴趣可以自行编译,在进行查询的时候可以通过开关打开CBO优化器功能allow_experimental_query_coordination。
以下为详细使用文档:
1. collect statistics
Analyze table hits
2. Show query plan explain
select * from hits settings allow_experimental_query_coordination=1
3. Explain with statistics explain statistics=1
select * from hits settings allow_experimental_query_coordination=1
4. Explain with cost explain cost=1
select * from hits settings allow_experimental_query_coordination=1
5. Show distributed query plan explain fragment
select * from hits settings allow_experimental_query_coordination=1
6. Set a hints and prefer to use two-stage aggregating explain fragment
select OS, count(*) from hits group by OS settings allow_experimental_query_coordination=1, cbo_aggregating_mode=’two_stage’
7. Show pepeline
Not implemented.
本作品采用 知识共享署名 4.0 国际许可协议 进行许可, 转载时请注明原文链接。