Aggregation is the most important operator in ClickHouse and also the most optimized one. This article attempts to analyze the internal implementation of ClickHouse’s aggregation operator, including the macro algorithm and underlying data structures.
P.S.: The analysis in this article is based on ClickHouse v24.7
1. Overview of Aggregation Algorithms
In ClickHouse, the implementation of the aggregation operator consists of three fundamental elements: the first is the HashMap; the second is parallel computation; and the third is two-phase aggregation.
As shown in the diagram below, T1, T2, and T3 are three threads. Each thread receives data and independently performs initial aggregation (pre-aggregate). The aggregated data is stored in a HashMap. Once all the data has been pre-aggregated, the intermediate results from the pre-aggregation are then aggregated again (final-aggregate). Considering concurrency issues, this step needs to be executed in a single thread, resulting in a fully aggregated HashMap, which is the final result.
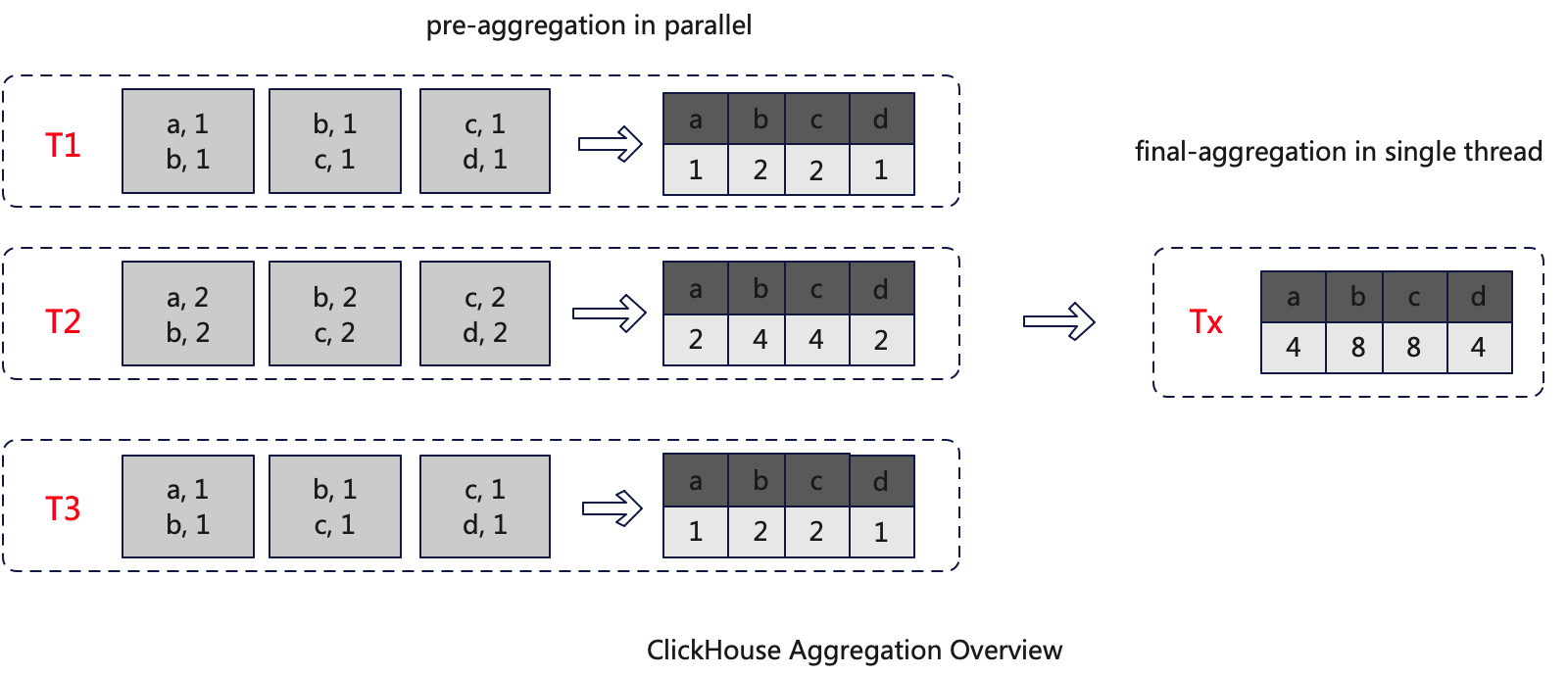
However, this algorithm has performance issues. Suppose the following scenario: the pre-aggregate has a low degree of aggregation, meaning the number of data entries does not significantly decrease after aggregation. In this case, the amount of data processed by the final-aggregate is essentially the same as that processed by the pre-aggregate. Since the final-aggregate is handled within a single thread, the processing time will be very long, thereby affecting query efficiency.
2. How to Optimize?
A straightforward approach to optimization is to parallelize the final-aggregate. However, parallelization involves concurrency issues, which is where a new data structure, the Two-level HashMap, comes into play.
2.1 Two-level HashMap
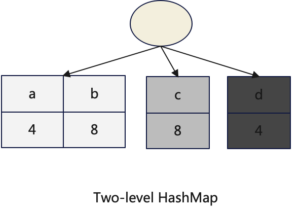
Compared to a conventional HashMap, a Two-level HashMap is a two-tier data structure. Data is first mapped to a bucket, which is a conventional HashMap, and then the data is further mapped to the buckets within the conventional HashMap. For more details on the Two-level HashMap, please refer to the following sections.
2.2 Optimized Algorithm
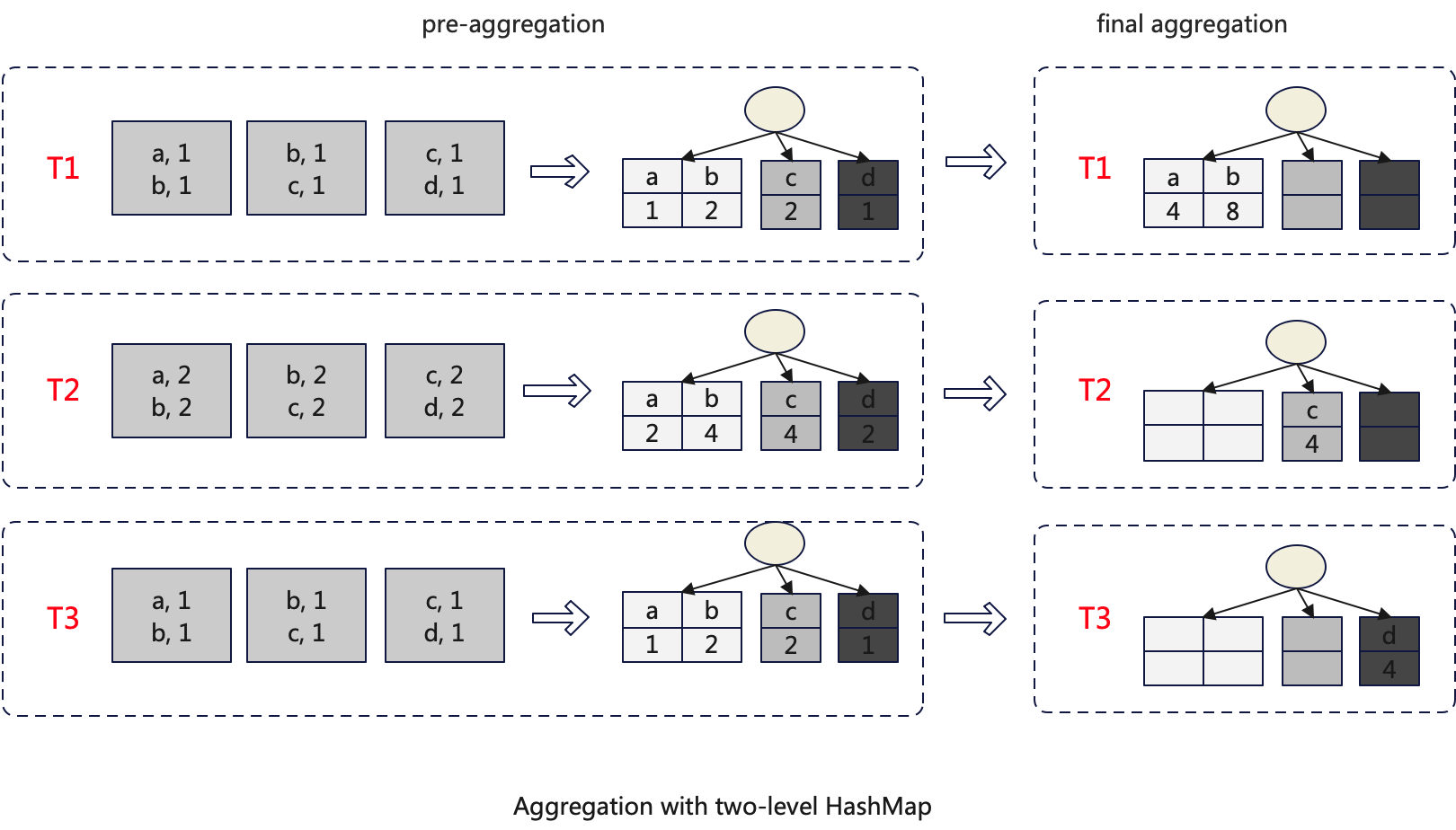
After employing the Two-level HashMap, the entire aggregation algorithm also needs to be adjusted. The adjustments mainly occur in the final-aggregate stage. Each sub-HashMap is processed independently within a separate thread to avoid concurrency issues, thereby achieving parallel processing.
2.3 How to Choose the Aggregation Algorithm?
ClickHouse provides a runtime adaptive method to select the aggregation algorithm and whether to use the Two-level HashMap.
The specific strategy is to convert the HashMap into a Two-level HashMap when the data in the HashMap exceeds a certain threshold during the pre-aggregate process. The relevant parameters are group_by_two_level_threshold and group_by_two_level_threshold_bytes.
Each pre-aggregate thread independently decides whether to use the Two-level HashMap. Therefore, during the second aggregation, the input might include both conventional HashMaps and Two-level HashMaps. In such cases, the conventional HashMap will be converted into a Two-level HashMap before the final-aggregate. The overall algorithm is illustrated in the following diagram:
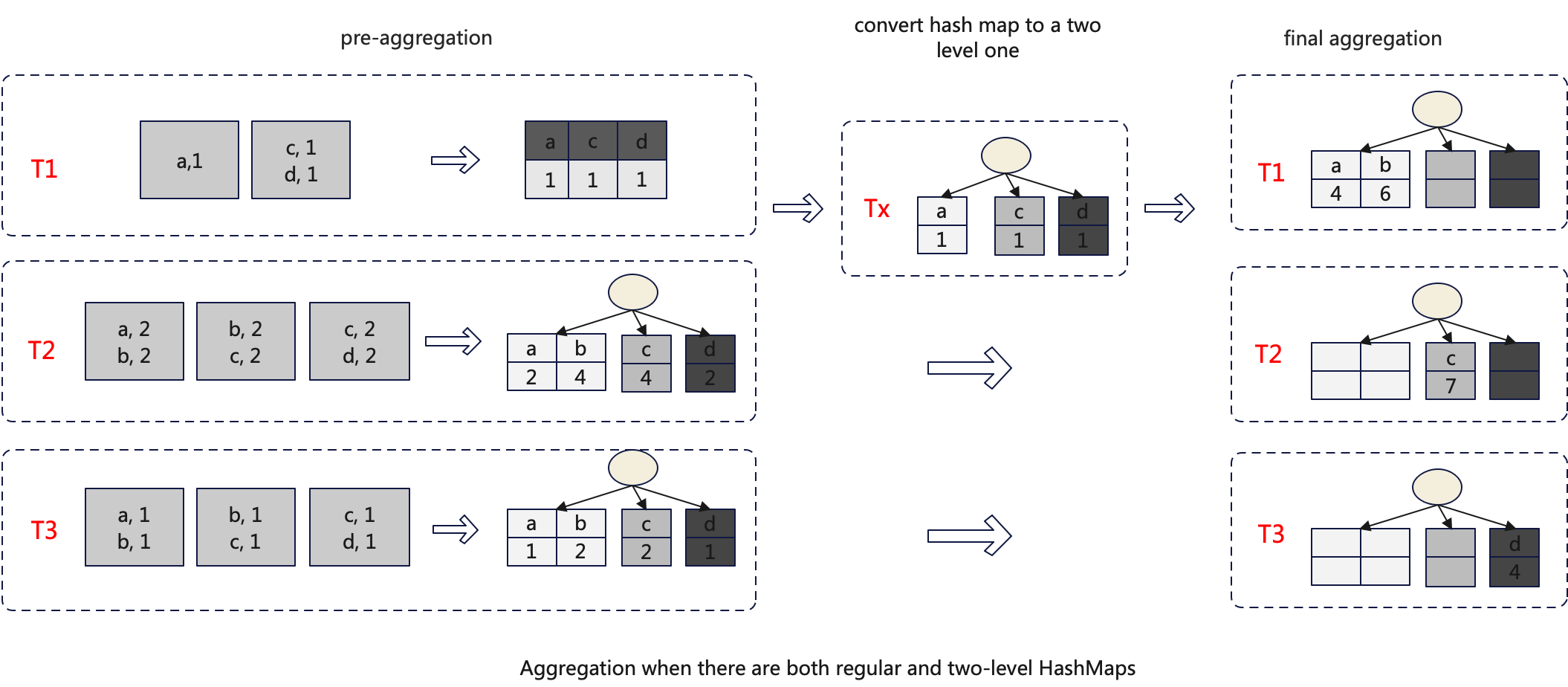
Currently, the conversion of a HashMap to a Two-level HashMap is handled within a single thread. Parallelizing this process would significantly enhance performance, making it a potential optimization point.
3. How to Build HashMap?
ClickHouse’s computational engine is a columnar engine, meaning that data storage and processing in memory are also column-oriented. Each input to an operator is referred to as a Block. A Block is a two-dimensional table composed of ( n ) columns, with its memory layout illustrated as shown below:
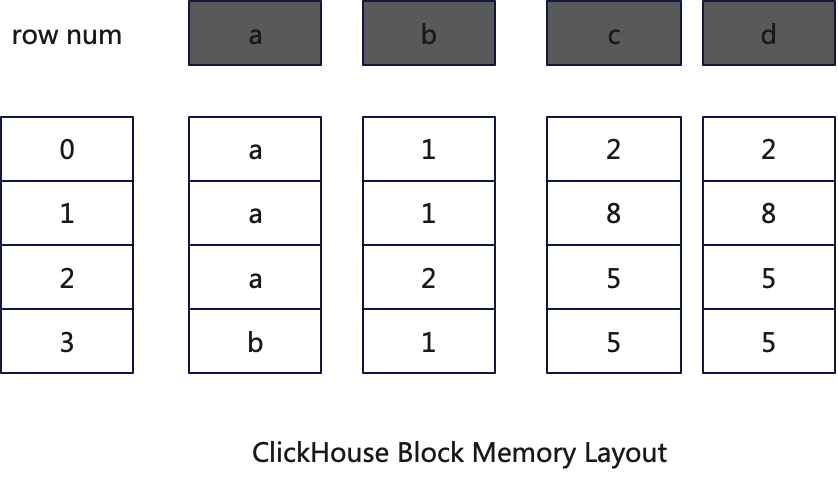
During the pre-aggregation phase, ClickHouse generates a HashMap from a Block. The specific process is as follows:
3.1 Build HashMap
For each row, ClickHouse checks whether the aggregation key exists in the HashMap. If it does not exist, the key is inserted into the HashMap. Memory required for the aggregation function’s state is then allocated via the Arena, and the memory structure of the state object for the aggregation function is initialized. Note that at this point, only the memory space for the value corresponding to the key is allocated, and no aggregation operation is performed.
What is the state object of an aggregation function? For example, sum might be an Int64, while uniqExact could be a HashSet, etc.
The following is the critical code for creating the state object of the aggregation function during the Build HashMap phase:
/// 1. Allocate memory for aggregation functions
/// total_size_of_aggregate_states:the total memory used to store the state of all aggregation functions
/// aggregates_pool:is an Arena, which is used for memory allocation.
/// place:a pre-allocated contiguous memory space.
AggregateDataPtr place = result.aggregates_pool->alignedAlloc(total_size_of_aggregate_states, align_aggregate_states);
/// 2. For each aggregation function state, a corresponding object is created. For example, the sum function might be represented as AggregateFunctionSumData<Int64>
aggregate_functions[j]->create(place + offsets_of_aggregate_states[j]);At the same time, ClickHouse maintains a pointer to the memory address of the aggregation function state object for each row of data in the Block. This allows for quickly locating the corresponding aggregation function state data address by row number in the next step.
The diagram below shows the memory structure of the constructed HashMap:
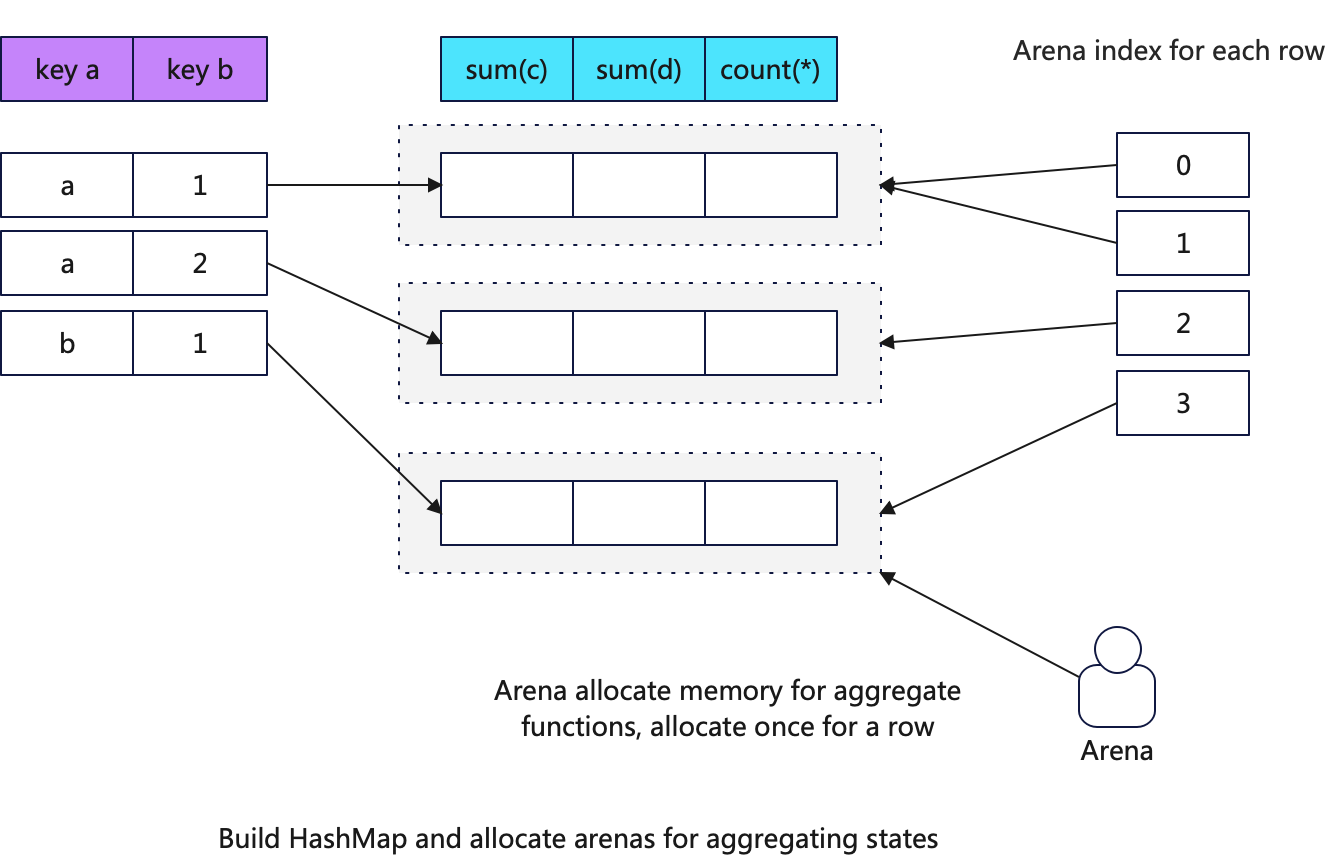
ClickHouse uses Arena for unified memory allocation for the states of aggregation functions, rather than the traditional new method. Why?
Because aggregation operations might consume a large amount of memory, and extensive memory usage requires monitoring and management. For example, it is necessary to limit the memory usage of a query or spill the state to disk when the memory usage reaches a certain threshold.
After this step, all key-value pairs are already present in the HashMap, but the values are in an empty state.
3.2 Execute Agregation
After constructing the HashMap, the aggregation operation can be executed. Here, the address index of the aggregation function state object is used to quickly locate the data address of the aggregation function, and then each aggregation function is applied. The diagram below shows the HashMap after aggregation:
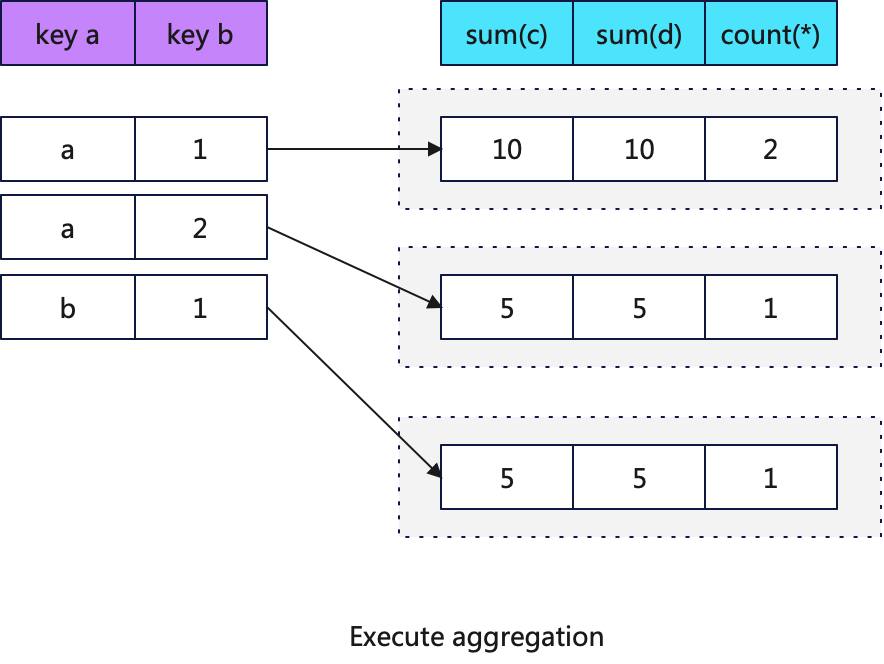
Since the results of the aggregation operations are distributed across multiple different memory addresses, they cannot be accelerated using SIMD instructions. Below is the key code for the aggregation operation:
/// Execute an aggregation function
void IAggregateFunctionHelper::addBatch( /// NOLINT
size_t row_begin,
size_t row_end,
AggregateDataPtr * places,
size_t place_offset,
const IColumn ** columns,
Arena * arena,
ssize_t if_argument_pos = -1) const override
{
for (size_t i = row_begin; i < row_end; ++i)
if (places[i])
static_cast<const Derived *>(this)->add(places[i] + place_offset, columns, i, arena);
}However, if the keys for the aggregation are all constant values, then there will be only one result. In this case, SIMD instructions can be used for optimization.
/// If aggregation keys are all constant values, SIMD can be used
template <typename Value>
void NO_INLINE AggregateFunctionSumData::addMany(const Value * __restrict ptr, size_t start, size_t end)
{
#if USE_MULTITARGET_CODE
if (isArchSupported(TargetArch::AVX512BW))
{
addManyImplAVX512BW(ptr, start, end);
return;
}
if (isArchSupported(TargetArch::AVX512F))
{
addManyImplAVX512F(ptr, start, end);
return;
}
if (isArchSupported(TargetArch::AVX2))
{
addManyImplAVX2(ptr, start, end);
return;
}
if (isArchSupported(TargetArch::SSE42))
{
addManyImplSSE42(ptr, start, end);
return;
}
#endif
addManyImpl(ptr, start, end);
}In the above code, a vectorized instruction dispatcher is used to select the optimal vectorized instructions for execution. For more details, refer to: cpu-dispatch-in-clickhouse.
Additionally, ClickHouse provides JIT (Just-In-Time) compilation to optimize aggregation operations. The parameter compile_aggregate_expressions controls whether JIT optimization for aggregation operators is enabled. In newer versions, this is enabled by default.
4. HashMap Optimization and Selection
HashMap is the most crucial data structure in aggregation operators, and its performance significantly impacts query efficiency. Therefore, ClickHouse has implemented extensive optimizations for HashMap.
The optimization approach in ClickHouse for aggregation scenarios involves selecting different HashMaps and hash functions based on the number and data types of aggregation keys. This specialized performance optimization strategy is widely utilized in ClickHouse.
Currently, ClickHouse offers over 30 different combinations of HashMaps and hash functions to handle various types of aggregation keys. For more details, refer to: AggregatedData.
Below is a brief introduction to these HashMaps by category:
4.1 Basic Structure of HashMap
ClickHouse uses an open addressing method for its HashMap. While the C++ standard library typically uses chaining to handle collisions, modern HashMaps often employ open addressing. Open addressing has several advantages over chaining:
- CPU Cache Line-Friendly: Provides higher cache hit rates.
- Avoids Memory Allocation During Insertion: Allocating memory space can be relatively slow.
- Saves Memory: Does not require pointers in linked lists.
- Simpler Implementation: No need to handle linked lists.
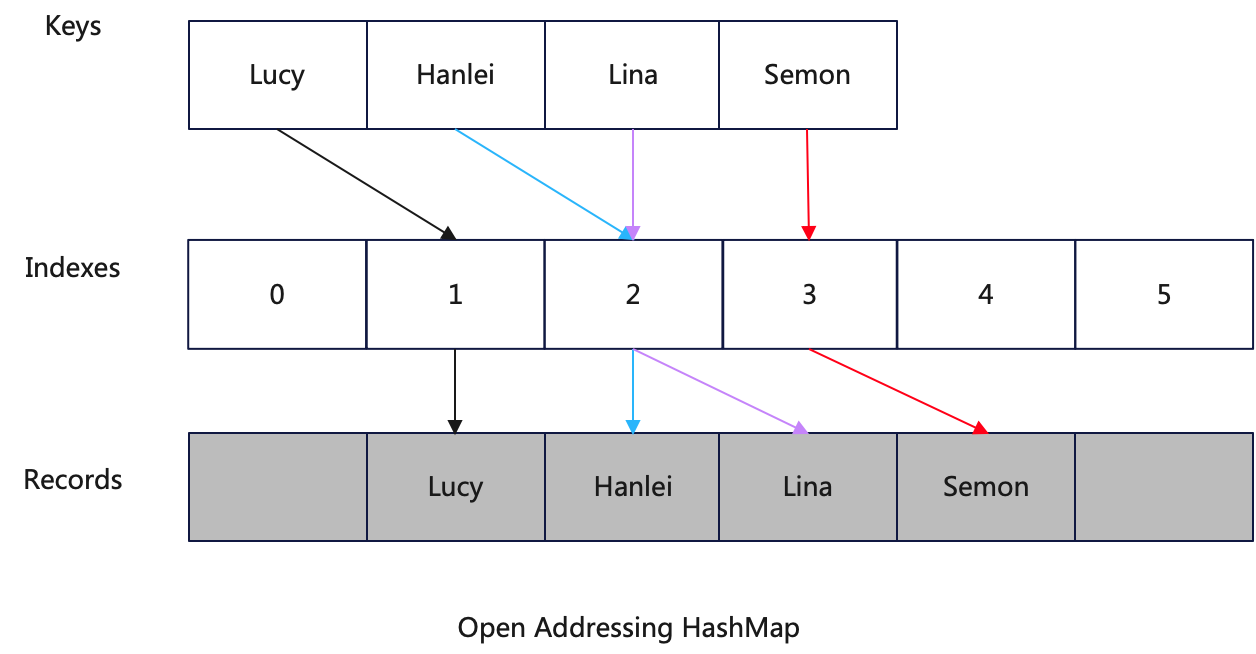
In aggregation scenarios, the choice of an open addressing HashMap is likely driven by the need to merge multiple HashMaps during the final-aggregate phase. This involves traversing the entire HashMap, and a CPU Cache Line-friendly HashMap can deliver better performance.
4.2 FixedHashMap
FixedHashMap is used for queries with a single aggregation key whose data type is either UInt8 or UInt16. Since the value space for these two data types is limited, their memory structure is set as a fixed continuous storage space based on their value range.
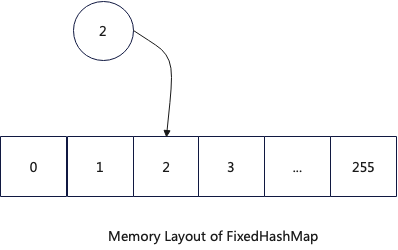
FixedHashMap has the following advantages:
- Extremely Efficient Hash Function: Numeric values can be used directly as hash values.
- No Collisions, Efficient Lookup: The hash value and the data have a one-to-one mapping.
- No Overhead from Resizing: Requests are handled smoothly.
4.3 StringHashMap
StringHashMap is used to store data of the String type and is a very commonly used HashMap. It is a composite data structure that incorporates multiple conventional HashMaps. Data is routed to different HashMaps based on the length of the key.
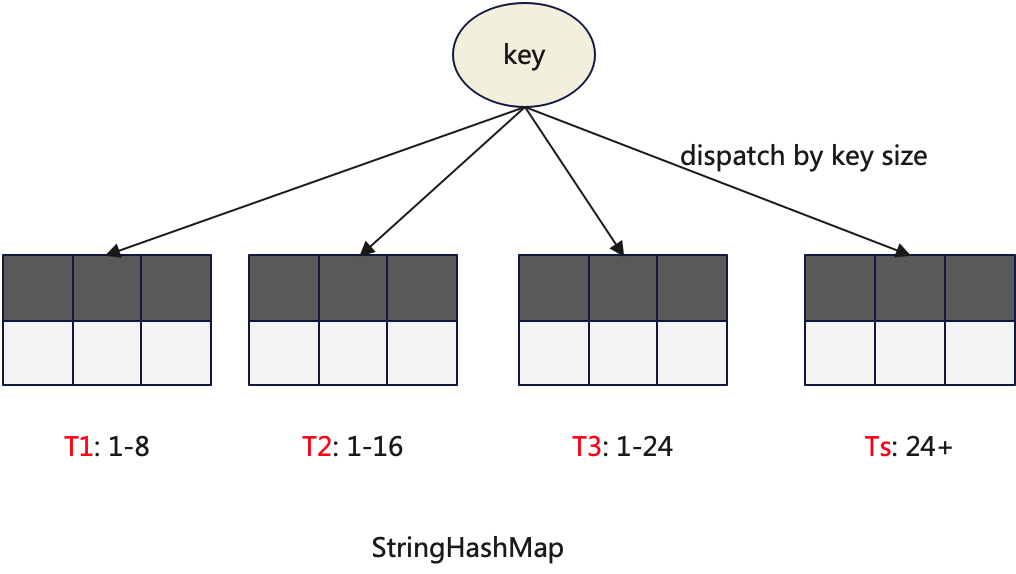
The first three sub-HashMaps use fixed-length key types. For instance, T1’s key is StringKey8 (UInt64), and T2’s key is StringKey16 (UInt128), allowing for the use of more efficient hash functions. Strings that are shorter than the required length are padded with zeros.
StringHashMap also uses customized hash functions, which are primarily implemented using the _mm_crc32_u64 function from SSE4.2.
struct StringHashTableHash
{
#if defined(__SSE4_2__)
size_t ALWAYS_INLINE operator()(StringKey8 key) const
{
size_t res = -1ULL;
res = _mm_crc32_u64(res, key);
return res;
}
size_t ALWAYS_INLINE operator()(StringKey16 key) const
{
size_t res = -1ULL;
res = _mm_crc32_u64(res, key.items[0]);
res = _mm_crc32_u64(res, key.items[1]);
return res;
}
size_t ALWAYS_INLINE operator()(StringKey24 key) const
{
size_t res = -1ULL;
res = _mm_crc32_u64(res, key.a);
res = _mm_crc32_u64(res, key.b);
res = _mm_crc32_u64(res, key.c);
return res;
}
......
#endif
size_t ALWAYS_INLINE operator()(StringRef key) const
{
return StringRefHash()(key);
}
};4.4 TwoLevelHashMap
TwoLevelHashMap has been previously introduced as the primary data structure that allows final aggregation to be parallelized. It contains a fixed set of 256 sub-HashMaps. It is noteworthy that accessing it does not require performing two separate hash computations. The first 8 bits of the hash value are used to select the sub-HashMap, while the remaining part of the hash value is used to select the bucket within the chosen sub-HashMap.
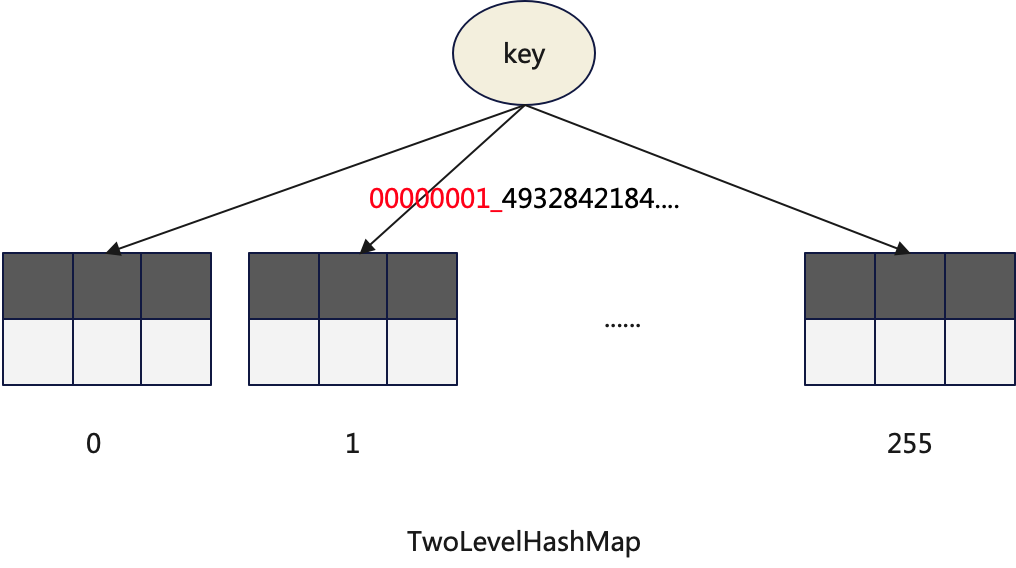
ClickHouse also provides a variant called TwoLevelHashMapWithSavedHash. Its key feature is that it saves the hash value, which can avoid recalculating the hash value when merging HashMaps.
5. Other Optimizations
5.1 Aggregate By Partition
If the group by columns in an aggregation query match the prefix of the table’s partition expression list, the aggregation algorithm can use a single-stage approach, directly skipping the final-aggregate. The optimization switch allow_aggregate_partitions_independently is off by default.
5.2 In-order Optimization
If the group by columns in an aggregation query match the prefix columns of the table’s order by keys, the aggregation operator can be optimized based on the ordered nature of the data. The optimization switch is optimize_aggregation_in_order. For more details, refer to The Inside Story of ClickHouse (6) Query Optimization Based on Order.
6. Conclusion
This article attempts to summarize the algorithms and important optimization methods for aggregation operators in ClickHouse. However, there are many other optimizations beyond this, such as:
- How does the final-aggregate phase merge HashMaps in sequence?
- What happens when memory is insufficient, and how does the operator spill data to disk?
- Is prefetching necessary when traversing the HashMap?
- How does the Pipeline execution engine support runtime changes to the execution plan?
- What are some low-level optimizations at the coding level, such as
inlineand__restrict?
The viewpoints expressed in this article are based on reading the ClickHouse source code and the author’s understanding. If you have any questions, feel free to reach out for discussion.
This work is licensed under a Creative Commons Attribution 4.0 International License. When redistributing, please include the original link.