Apache Druid是一款优秀的OLAP引擎,众所周知数据存储格式对一款存储系统来说是最核心的组件,Druid的数据格式是自定义的,以此保证了在海量数据下的亚秒级查询。本文深入分析Druid V1版本数据存储格式,包括索引结构和数据在磁盘中的存储方式。在阅读本文之前希望您对Druid和数据存储有简单了解。
Druid的存储方式是列式的,每个列为一个逻辑文件,列与列之间的数据格式是相对独立的。与传统OLAP系统一样,Druid的列分为维度与度量两种,其中维度列因为需要被检检索,所以设计了索引,维度列的数据格式也是Druid数据结构的核心;相对的度量列只需要存储行值就可以。为了方便阐述数据格式,本文以一个广告效果分析作为例子进行分析,图1中是样例数据,请一定注意它是聚合后的数据,而不是原始数据。
维度数据结构
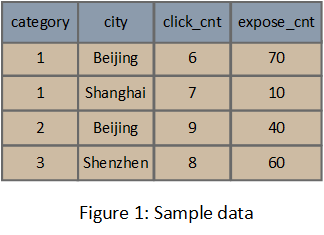
上文提到维度是Druid存储结构的核心,并且各个维度是相对独立存储的,所以我们可以通过分析单个维度的数据结构,来窥探Druid的存储结构。图2展示了“city”维度和两个度量的逻辑存储结构,整体上Druid维度的索引包含三部分:字典、编码后的维度值、倒排索引,接下来详细分析这三部分。
字典
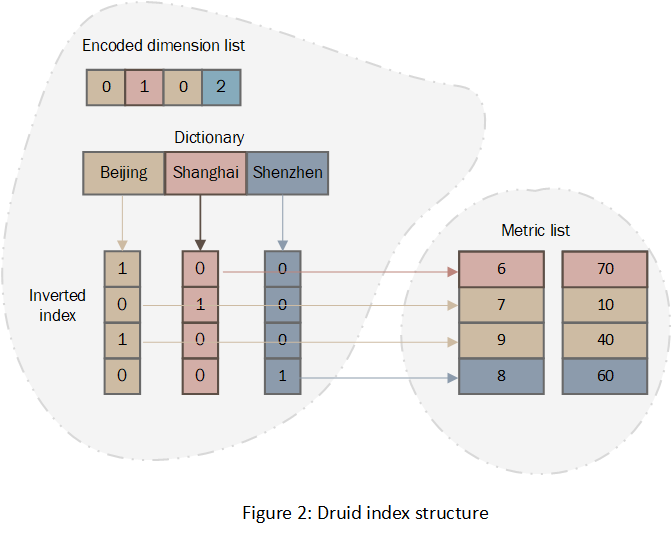
字典是将列的所有值去重,然后按照字典顺序排序的值组成的数组,虽然字典中只存储了排序后的维度值,但是它还隐含了另一个信息,那就是每个维度值的编码值,编码值就等于数组的下标。字典的设计目的有两个:一是维度值可以使用编码后的整数表示,而不是实际的值,编码值一般可以节约存储空间;二是编码后的整数是定长的,磁盘中定长存储可以省去定位单个值的offset length等索引信息的开销,最终还是能节省存储空间。
图3展示了Druid字典的逻辑结构和物理结构,Druid字典采用了线性的数组结构。因为字典中的值是不定长的,所以物理结构中有一段index部分,其中记录了每个值的offset;data部分每个值的头部记录了该值的长度。这样的设计才能定位到任意一个行的值。
编码后的维度值
Druid是一个预聚合的方案,但是其聚合不是按照一个维度的group-by聚合,而是按照所有维度的group-by聚合,对于图1中的数据已经是按照聚合过了。可以看出对于单一维度而言,编码过后的维度值依然可能重复,所以每个维度的行信息不能用字典代替,而需要额外存储。
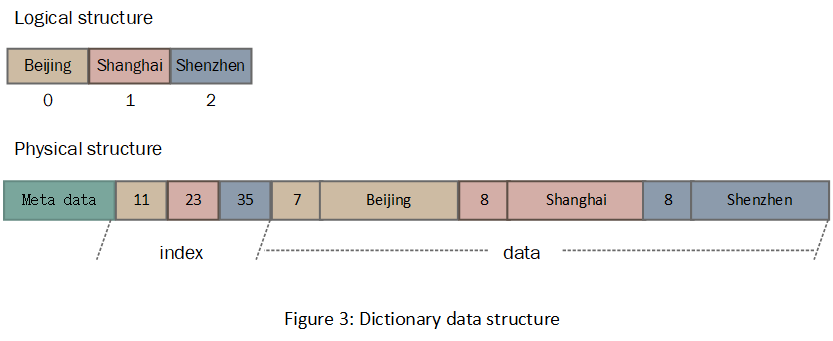
编码后的维度值都是一个个的整数。为了保证单一值在磁盘中能快速定位,在整个维度范围内这些整数需要是定长的,因为定长元素组成的数组可以通过计算直接定位到某一个元素。同时为了节约存储空间这些整数不一定需要用4个字节表示,它的长度取决于该维度在单一数据文件内的唯一值的数量,Druid采用了采用了变长整数编码的方式,具体如下:
1 – 2^8-1 => 1 byte
2^8 - 2^16-1 => 2 bytes
2^16 - 2^24-1 => 3 bytes
2^24 - 2^32-1 => 4 bytes
2^32 - 2^40-1 => 5 bytes
...以图1中“city”维度为例,它包含唯一值3个,所以每个值用1个字节表示。
图4展示了编码后维度值的逻辑结构和物理结构,在逻辑上整个维度是一个线性的结构,但是在物理存储上数据结构中包含了offset索引和元素length部分,这很明显是存储非定长数据的。原来Druid将整个线性结构首先划分成了一个个分组,每个分组大小不超过64KB,而分组又进行了压缩,压缩后的分组已经是非定长的了,所以站在整个数据结构的角度,需要按照非定长数据的格式进行存储。
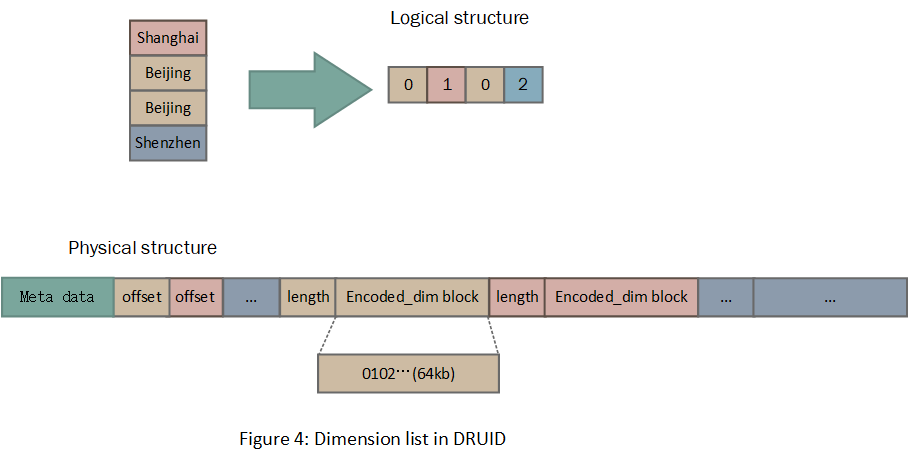
将整个整数数组进行分组压缩的设计思路,其背后的考量点主要是:一是对于磁盘存储压缩是有必要的,因为能减小空间占用和传输消耗;二是分组也是有必要的,因为绝大多数读取数据的场景不会涉及到所有的分组,而是部分分组,分组后一次查询只涉及到了少数分组,对于查询速度的提升有极大帮助。
倒排索引
最后是倒排索引部分,对于字典中的每个元素,Druid都会生成一个Bitmap,其中1表示该bit下标对应的行的值是对应字典元素的值,反之不是。
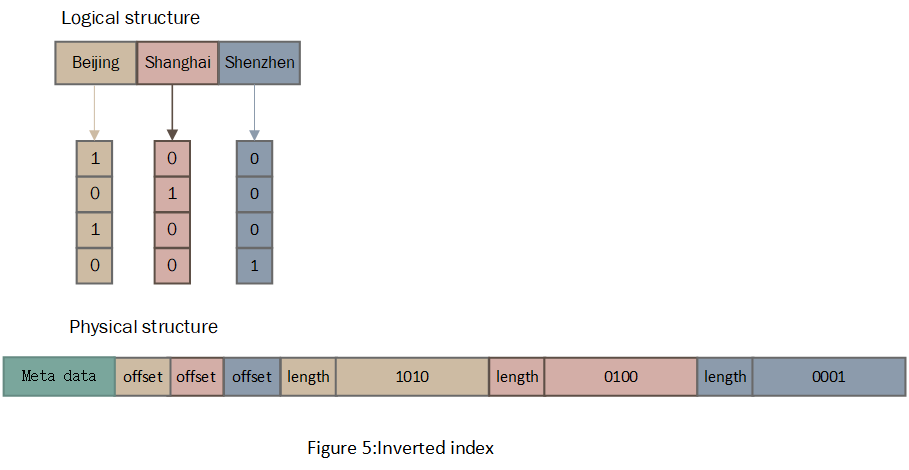
Bitmap数据是基于聚合后的数据的,所以它的长度和原始数据的行数是没有关系的。从图5中“Beijing”对应的Bitmap可以看出,它基于图1中的聚合后的数据,而不是原始数据,所以Bitmap的长度是4。
Druid的反向索引采用的是Bitmap的方案,因为字典中每个元素对应的Bitmap的长度都是一样的,所以物理存储上可以采用定长的方式?其实不是的,出于节省存储空间的考虑,Druid将每个Bitmap进行了压缩,一般Bitmap数据结构的压缩比例是比较大的,所以压缩的是有必要的。因为压缩后数据长度不相同了,所以存储上需要按照非定长数据进行存储。
数组
Druid是支持数组数据类型维度的,对于数组数据类型Druid如何存储呢?整体上数组的存储方式还是字典、编码后的维度值、倒排索引三个部分。其中字典和倒排索引部分是跟单值类型的维度的存储方式没有任何区别。
但是在编码后的维度值部分是有区别的,对于单值维度这部分的逻辑结构是一个线性列表(这里暂时不考虑分组),但是对于数组类型的维度,它其实是一个二层的层次结构,外层是一个非定长的线性列表,线性列表的每个元素也就是内层,是一个定长的线性列表。对于整个数据结构来说,在物理结构上依然可以进行分组和压缩。
存储结构小结
对于物理结构来说其元素是否定长,对其存储方式起到决定作用,图6总结了定长和非定长的存储模式,请注意这里没有考虑分组和压缩。
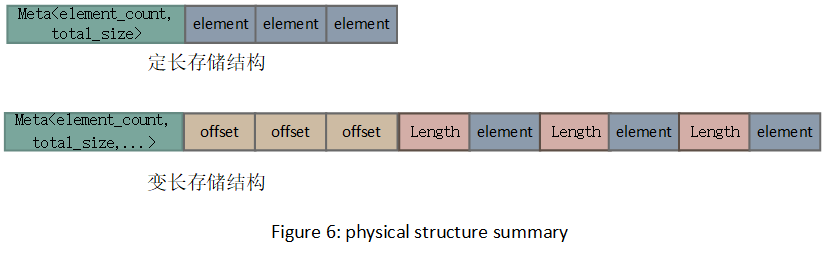
Druid对线性非定长存储结构有这大量的应用,它遵循图6的总结,只是在元数据部分稍有不同,现总结如下:
version:占用 1byte
allowReverseLookup:1byte ,是否允许反向查找,指根据Value反查index, 用于Dictionary字典查找
numBytesUsed :4bytes ,所占字节数
numElements:4bytes,元素的总数量
如何使用
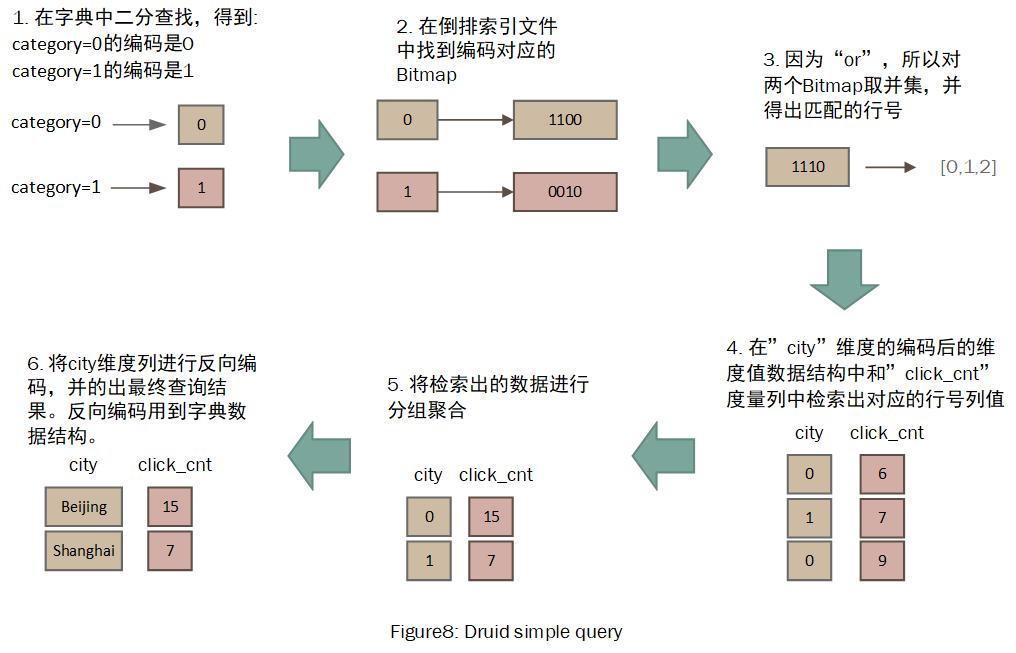
最后简单分析下Druid在查询中如何使用到以上数据结构,为了聚焦问题,假设查询只命中了一个数据文件,这样可以忽略多个数据文件的结果合并等问题。我们以下面简单查询为例:
select city, sum(click_cnt) from table_t where category=0 or category=1 group by city图8展示了查询流程,其中第1.6步用到了字典结构,第3步用到了倒排索引数据结构,第4部用到了编码后的维度值数据结构。
本作品采用 知识共享署名 4.0 国际许可协议 进行许可, 转载时请注明原文链接。