Java HashMap是一个简单的数据结构,Java中很多其他种类的Hash结构包括HashSet、HashTable、ConcurrentHashMap等都是基于它的。同时Hash是一种很通用的数据结构,在不同场景下Hash的策略不一样,通过Java中的HashMap我们理解基本Hash的实现方式,希望能对我们在工作中不同场景下对Hash结构的使用与理解有所帮助。
Java HashMap是一种数据结构,那么我们先从数据结构的角度来看它。HashMap内部基础数据结构由数组与链表组成,如下图,图中每个元素代表一个键值对,数组结构中每个键值对的键的Hash值都不同,相反链表结构中每个键值对的键的Hash值都相同,也就是说HashMap采用链表的方式处理冲突,知道了基础数据结构,那么构建在之上的操作就很好理解了。
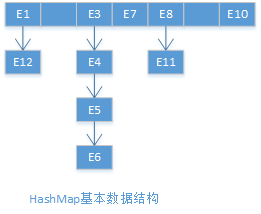
在深入介绍HashMap之前我们先来看一下HashMap内部的一些重要的逻辑变量,这些变量与我们之后介绍HashMap的工作机制紧密相关。
- size:HashMap中存贮的键值对的个数
- capacity:数组数据结构的长度
- loadfactor:默认值为0.75,用于计算threshold,与HashMap Rehash紧密相关
- threshold:threshold=capacity*loadfactor,当size>=threshold时再次put需要
- ReshashmodCount:HashMap的映射关系修改的次数
接下来我们看put操作,put操作分三种情况,第一种情况是需要被put的键值对在HashMap中不存在(键值对中的键不存在于HashMap中),并且通过Hash操作计算出来的index,没有发生冲突(数组结构中index位置是空的),此时只需要把它放到数组结构对应索引的位置就好;第二种情况是需要被put的键值对在HashMap中不存在,但是通过Hash操作计算出来的index发生了冲突,此时需要把它放到链表结构中,HashMap中是放到链表结构的头部;第三种情况是键值对已经存在于HashMap中,此时只要替换值就ok了。值得注意的是当执行put操作的时候如果发现size>=threshold,则HashMap首先会Rehash,之后再执行put操作,Rehash操作留待后文再讲。
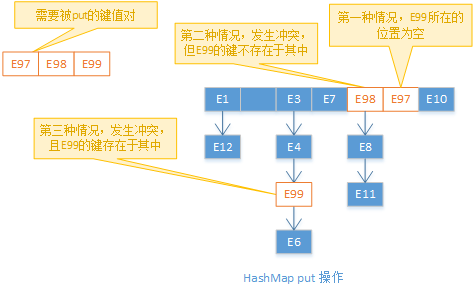
get操作比较简单,首先计算hash值,Java中每个对象都有的hashCode方法就会在hash方法中被调用,其次通过hash值计算出键在数组结构中所对应的index,如果index位置为空则返回空,否则遍历链表结构,如果键相等就返回次键的值,如果遍历结束都没有找相等的键就返回空。由此可见如果冲突过多的话,get操作的时间会变的很长,极端情况数组结构只有一个节点,那么HashMap则完全退化成链表结构,查询的时间复杂度不在是O(1)而是O(N)。如果我们在创建HashMap的时候将loadfactor参数设置的很大,当数组中元素过多,就会导致冲突过多,从而导致查询缓慢。
接下来再看遍历操作,我们首先来看遍历的逻辑,对于数组结构从左至右,对于链表结构则由上至下。文章开头图片中的HashMap的遍历顺序为:E1->E2->E3->E4->E5>E6->E7->E8->E11->E10。HashMap的遍历操作通过java.util.Iterator接口实现。主要遍历逻辑在java.util.HashMap.HashIterator抽象类中,当我们遍历HashMap的时候会调用HashIterator的nextEntry方法。HashIterator代码如下:
private abstract class HashIterator<E> implements Iterator<E> {
Entry<K,V> next; // next entry to return
int expectedModCount; // For fast-fail
int index; // current slot
Entry<K,V> current; // current entry
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
}
public final boolean hasNext() {
return next != null;
}
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}
public void remove() {
if (current == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Object k = current.key;
current = null;
HashMap.this.removeEntryForKey(k);
expectedModCount = modCount;
}
}上述代码中大家有没有看到一个熟悉的异常呢,对了就是ConcurrentModificationException,我们来看看它是怎么产生的。首先我们明确一点HashIterator是HashMap的内部类,它能访问HashMap的字段比如modCount。首先新建HashIterator实例的时候设置expectedModCount = modCount,所以正常情况下进行遍历的时候nextEntry方法中的对expectedModCount与modCount相等的判断都是ok的。我们想象这样一个场景,在遍历的同时,如果另外一个线程也持有对该HashMap的引用,并且调用了put、remove或clear方法,改变了HashMap的键值映射结构,此时使modCount++,遍历线程中的下一次对nextEntry方法的调用就会抛出ConcurrentModificationException。
我们想一想HashMap为什么要进行这样的设置呢。在遍历HashMap的过程中,HashMap的内容发生了改变,如果此时遍历继续进行,那么遍历出来的结果可能就不是我们一开始想要的内容了。这种尽早发现问题可能存在的情况并且中断操作抛出异常的做法,我们称之为fail-fast原则。
其实还有另外一种比较典型的ConcurrentModificationException的场景。就是在我们遍历HashMap的时候,通过hashMap的put、remove、clear方法来改变HashMap的映射关系。
对于前文提到的改变HashMap的映射关系,指的是操作过后HashMap的元素的个数发生了改变,这样的操作包括put、remove、clear。但是put方法如果被put的键值对已经存在于HashMap中,则不会改变HashMap的映射关系,从而不会导致modCount++,进而不会引起ConcurrentModificationException。
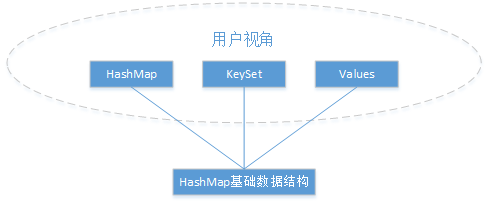
通过HashMap能得到一个keySet与一个values,他们的数据类型分别是HashSet与Collection。那么大家有没有想过他们内部到底是怎么实现的呢,是不是分配了内存空间,拷贝对应的数据新的空间呢。其实不是这样的,通过HashMap的到的keySet与values都是构建在HashMap基础数据结构之上的,并没有重新分内存空间,也就是说三个数据结构是同相同的内存空间,相同的数据结构以及相同的数据。基于此HashMap、HashMap衍生的keySet、HashMap衍生的values中的任意一个对自身的修改操作都对其它两个有影响。另外keySet与values不支持put操作,并且他们的remove与clear操作也必须通过Iterator才能完成。它们三个的遍历操作都是基于HashIterator的,所以keySet与values也同样存在ConcurrentModificationException的问题。
最后我们来看HashMap的Rehash操作。当我们创建一个HashMap的时候可以传入initCapaity参数,HashMap会将initCapaity赋值给threshold,这里是HashMap设计上逻辑不合理的地方,按照一贯逻辑threshold应该为initCapaity*loadfactor,当然它这种设计使得用户更容易理解。其实在HashMap第一次分配内存的时候依然会对initCapaity做出调整,新的值为第一个大于initCapaity的2的N次方的整数值。更当我们向HashMap中添加数据的时候,如果发现size>=thredshold则进行Rehash,HashMap采用2倍扩容的策略,即新的数组元素个数为之前的两倍,当然总个数不能超过Integer.MAX_VALUE因为size为一个整形值。分配好空间之后,在用户线程中直接迁移数据,此时会阻塞用户线程,迁移好之后引用切换,使用新分配的数组。
本作品采用 知识共享署名 4.0 国际许可协议 进行许可, 转载时请注明原文链接。