本文记录生产环境一次Kylin偶尔查询缓慢问题以及问题分析。
问题描述
业务反馈查询缓慢,通过日志查看确实有查询慢的现象。像下面的查询,总共扫描了11行数据,数据量121bytes,一般来说查询时间不应该超过一秒,但实际上查询却耗费了108秒,查询缓慢现象很明显。
==========================[QUERY]===============================
Query Id: 4f10b2e7-9109-4afa-a594-bd665c0d429e
SQL: select sum(search_times) as "搜索量" ,sum(down_times) as "下载量" from xxx where dayno >= '20180707' and dayno <= '20180717' order by "搜索量" desc limit 10000
User: ADMIN
Success: true
Duration: 108.857
Project: easydata
Realization Names: [CUBE[name=xxxxx]]
Cuboid Ids: [1048576]
Total scan count: 11
Total scan bytes: 121
Result row count: 1
Accept Partial: true
Is Partial Result: false
Hit Exception Cache: false
Storage cache used: false
Is Query Push-Down: false
Is Prepare: false
Trace URL: null
Message: null
==========================[QUERY]===============================问题分析
对于Java进程的卡顿问题,首先想到的是是否是GC停顿导致的。下图是“jstat -gcutil PID 1000 300”命令的输出结果:
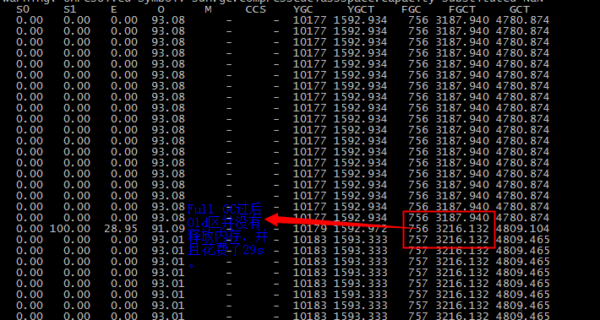
从图中可以看出JVM的OLD区一直保持93%的使用率,空闲空间比例很低。图中可以看出发生了一次Full GC,Full GC花费时间是29秒,并且Full GC过后,OLD区域并没有释放内存。至此我们可以得出部分结论:JVM中有大量的数据在较长时间内占用内存空间,由于内存紧张,容易导致频繁的Minor GC和Full GC,并且GC的时间很长。通过kylin进程的GC日志也能证明以上结论,很明显这种情况是导致查询延迟的原因之一。
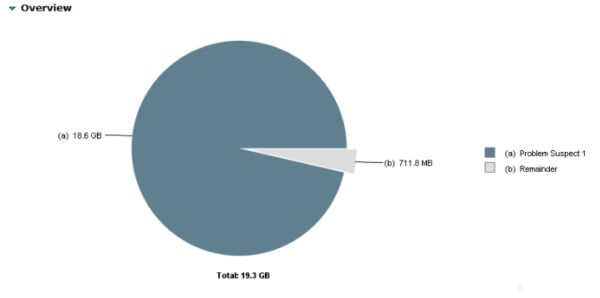
接下来我们需要知道是什么数据长时间占用这么大量的JVM内存。方式很简单,首先dump进程的内存,然后通过MAT进行分析。通过MAT的内存泄漏概览页面,发现有一个18.6GB的对象,看来它就是罪魁祸首。
接下来跟进该对象的引用关系,定位到这个18.6GB的对象是“DictionaryManager”里的“dictCache”字段,通过引用关系可知,它是一个“LocalCache”类,可以简单看做是一个Map类。下图是对象引用关系图:

我们在跟进kylin代码,看看“DictionaryManager.dictCache”里存放的是什么。
@see DictionaryManager
public class DictionaryManager {
...
private LoadingCache<String, DictionaryInfo> dictCache; // resource
private DictionaryManager(KylinConfig config) {
this.config = config;
this.dictCache = CacheBuilder.newBuilder()//
.softValues()//
.removalListener(new RemovalListener<String, DictionaryInfo>() {
...
})//
.maximumSize(config.getCachedDictMaxEntrySize())//
.expireAfterWrite(1, TimeUnit.DAYS).build(new CacheLoader<String, DictionaryInfo>() {
@Override
...
}
});
}
private DictionaryInfo saveNewDict(DictionaryInfo newDictInfo) throws IOException {
save(newDictInfo);
dictCache.put(newDictInfo.getResourcePath(), newDictInfo);
return newDictInfo;
}
...
}从上边摘录的代码可以看出,“DictionaryManager.dictCache”是一个有一天过期时间的LocalCache,里边存放的是cube的字典信息。这里解释下kylin中字典是什么,在kylin中对于每一个维度,在Hbase中并不存储维度的每个实际值,而是将每个维度值编码为一个整数,而维度值与编码后的整数值的映射关系就为字典。
我们在回到MAT分析页面,看看到底是什么字典占用了这么多内存。

可以看到占用内存的主要是“aaa”的字典信息。接下来在到kylin元数据目录统计下字典情况:
du -shm * | sort -n -r | head -n5
21531 aaa
3010 bbb
2955 ccc
1792 ddd
1314 eee“aaa”的字典总共占用21GB的磁盘空间,相比其它cube大太多。进一步统计得出是“URL”这个字段太大(21G)。并且从Hive表里查出“URL”字段一天的基数集大小为758w,严重超过了kylin的正常区间。
解决方案
优化”aaa”,减少维度的基数大小。
本作品采用 知识共享署名 4.0 国际许可协议 进行许可, 转载时请注明原文链接。