RaftKeeper是一款C++版本的Zookeeper,其写操作性能是ZooKeeper的2倍,查询TP99更稳定,可以参考benchmark。RaftKeeper目前已经开源欢迎大家试用。
RaftKeeper的基于Raft一致性协议,其Raft Core部分使用了eBay开源的NuRaft。本文记录了一次团队在leader频繁切换场景下导致的NuRaft日志不一致,进而导致数据不一致的问题。
问题描述
三个节点组成的集群,其中节点13的数据跟其它两个节点不一致。集群拓扑:
ID: 13 10.199.141.8
ID: 14 10.199.141.7
ID: 15 10.199.141.6问题分析
我们制作了一个工具可以解析RaftKeeper的log,发现在区间[989286-989299]内节点13的log与其它两个节点不一致。
通过日志发现在log不一致时间2022.02.25 12:26左右,存在3次leader切换: 13(Term=41, ), 14(Term=42, idx=989286), 13(Term=43,idx=989300), 14 (Term=44,idx =989303)。
以下节点13的日志显示了当节点14 (Term=44, idx=989303)成为leader后, 节点13接收到14的append_entries请求,使用14的日志覆盖本地的日志,覆盖到989300为止。
2022.02.25 12:26:21.470207 [ 26429 ] {} <Debug> RaftInstance: Response back a append_entries_response message to 14 with Accepted=0, Term=44, NextIndex=989314
2022.02.25 12:26:21.470416 [ 26436 ] {} <Debug> RaftInstance: Receive a append_entries_request message from 14 with LastLogIndex=989301, LastLogTerm=42, EntriesLength=2, CommitIndex=989279 and Term=44
2022.02.25 12:26:21.470450 [ 26436 ] {} <Debug> RaftInstance: Response back a append_entries_response message to 14 with Accepted=0, Term=44, NextIndex=989314
2022.02.25 12:26:21.470668 [ 26438 ] {} <Debug> RaftInstance: Receive a append_entries_request message from 14 with LastLogIndex=989300, LastLogTerm=42, EntriesLength=3, CommitIndex=989279 and Term=44
2022.02.25 12:26:21.470704 [ 26438 ] {} <Debug> RaftInstance: Response back a append_entries_response message to 14 with Accepted=0, Term=44, NextIndex=989314
2022.02.25 12:26:21.470935 [ 26439 ] {} <Debug> RaftInstance: Receive a append_entries_request message from 14 with LastLogIndex=989299, LastLogTerm=42, EntriesLength=4, CommitIndex=989279 and Term=44
2022.02.25 12:26:21.470976 [ 26439 ] {} <Debug> RaftInstance: [INIT] log_idx: 989300, count: 0, log_store_->next_slot(): 989314, req.log_entries().size(): 4
2022.02.25 12:26:21.471001 [ 26439 ] {} <Debug> RaftInstance: [after SKIP] log_idx: 989300, count: 0
2022.02.25 12:26:21.471013 [ 26439 ] {} <Information> RaftInstance: rollback logs: 989300 - 989313, commit idx req 989279, quick 989285, sm 989285, num log entries 4, current count 0
2022.02.25 12:26:21.471034 [ 26439 ] {} <Information> RaftInstance: rollback log 989313, term 44
2022.02.25 12:26:21.471043 [ 26439 ] {} <Information> RaftInstance: rollback log 989312, term 44
2022.02.25 12:26:21.471051 [ 26439 ] {} <Information> RaftInstance: rollback log 989311, term 43
2022.02.25 12:26:21.471060 [ 26439 ] {} <Information> RaftInstance: rollback log 989310, term 43
2022.02.25 12:26:21.471069 [ 26439 ] {} <Information> RaftInstance: rollback log 989309, term 43
2022.02.25 12:26:21.471077 [ 26439 ] {} <Information> RaftInstance: rollback log 989308, term 43
2022.02.25 12:26:21.471086 [ 26439 ] {} <Information> RaftInstance: rollback log 989307, term 43
2022.02.25 12:26:21.471094 [ 26439 ] {} <Information> RaftInstance: rollback log 989306, term 43
2022.02.25 12:26:21.471102 [ 26439 ] {} <Information> RaftInstance: rollback log 989305, term 43
2022.02.25 12:26:21.471111 [ 26439 ] {} <Information> RaftInstance: rollback log 989304, term 43
2022.02.25 12:26:21.471119 [ 26439 ] {} <Information> RaftInstance: rollback log 989303, term 43
2022.02.25 12:26:21.471128 [ 26439 ] {} <Information> RaftInstance: rollback log 989302, term 43
2022.02.25 12:26:21.471141 [ 26439 ] {} <Information> RaftInstance: rollback log 989301, term 43
2022.02.25 12:26:21.471153 [ 26439 ] {} <Information> RaftInstance: revert from a prev config change to config at 934352
2022.02.25 12:26:21.471161 [ 26439 ] {} <Information> RaftInstance: overwrite at 989300, term 42
2022.02.25 12:26:21.471173 [ 26439 ] {} <Information> LogSegment: Truncating log_1_open_20220225113536, offset 989299, first_index 1, last_index from 989313 to 989299, truncate_size to 449073886覆盖到989300为止表示,原因是节点13认为它自己在idx=989299处的日志跟节点14是一样的。
Raft中判断两个节点日志相同的标准是什么呢?答案是日志的id相同并且term相同,可以参考handle_append_entries函数
// Skipping already existing (with the same term) logs.
while ( log_idx < log_store_->next_slot() &&
cnt < req.log_entries().size() )
{
if ( log_store_->term_at(log_idx) ==
req.log_entries().at(cnt)->get_term() ) {
log_idx++;
cnt++;
} else {
break;
}
}节点13认为它自己在idx=989299处的日志跟节点14是一样的,说明它本地的idx=989299处的日志的term跟节点14 idx=989299日志的term是一样的。
下面分析节点13跟14在idx=989299日志出的term到底是什么。
下图是根据节点13和节点14的日志绘制的时间线,其记录了3次leader切换的流程。
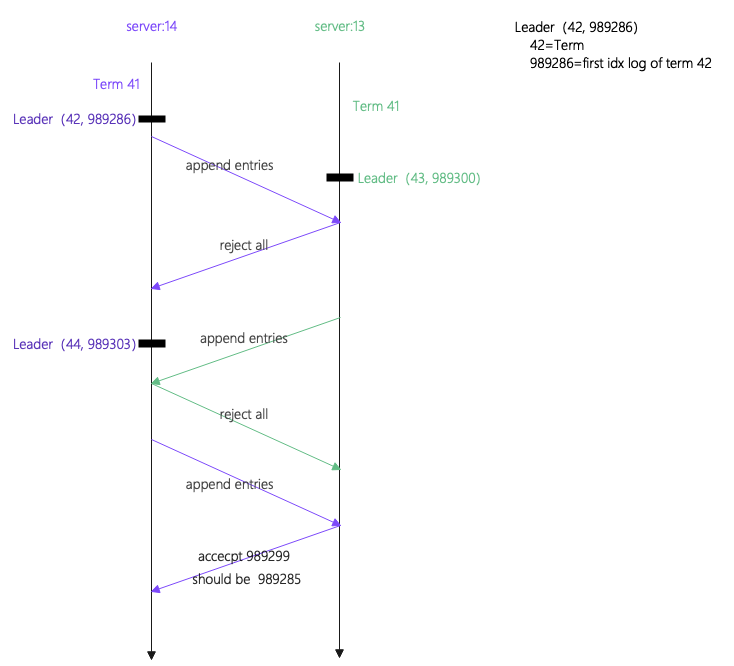
从图中可以看到当节点14在任期42(term=42)处成为leader后向节点13发送append_entries请求,此时节点13成为新的leader任期是43(term=43),因为任期更新,所以它拒绝了节点14的这次append_entries请求。那么此时节点13上的idx=989299日志的term应该是41,但是实际上是42,这显然是不对的。
继续调研节点13 idx=989299日志的term是如何设置的。在节点13上发现以下日志:
2022.02.25 12:26:21.216310 [ 26428 ] {} <Debug> RaftInstance: Receive a client_request message from 0 with LastLogIndex=0, LastLogTerm=0, EntriesLength=1, CommitIndex=0 and Term=0
2022.02.25 12:26:21.216473 [ 26426 ] {} <Debug> RaftInstance: Receive a append_entries_response message from peer 15 with Result=0, Term=42, NextIndex=989285
2022.02.25 12:26:21.216723 [ 26426 ] {} <Information> RaftStateManager: save srv_state with term 42 and vote_for -1
2022.02.25 12:26:21.216721 [ 26428 ] {} <Debug> RaftInstance: append at log_idx 989299
2022.02.25 12:26:21.216790 [ 26428 ] {} <Debug> RaftInstance: commit_ret_cv 989299 0x7f476af04d20 sleep通过日志我们可以看到节点13在任期41期间收到客户端的写请求,并记录日志,日志idx=989299,此时日志的term应该是41,但是在这个操作序列期间,节点13收到了节点15的append_entries请求,并将自己的term更新为了42,从而导致节点13将idx=989299的日志的term错误设置成了42。
下图展示了节点13处理append_entries请求和用户请求两个线程的事件处理时间线
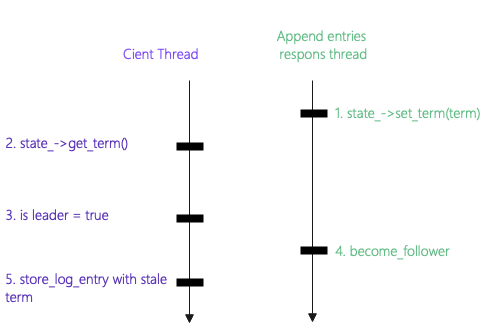
可以清晰的看到在处理append_entries请求的过程中在更新节点term和更新节点状态两个操作间没有lock保护导致的。确认NuRaft代码如下:
bool raft_server::update_term(ulong term) {
if (term > state_->get_term()) {
state_->set_term(term);
state_->set_voted_for(-1);
state_->allow_election_timer(true);
election_completed_ = false;
votes_granted_ = 0;
votes_responded_ = 0;
ctx_->state_mgr_->save_state(*state_);
become_follower();
return true;
}
return false;解决方案
在处理append_entries请求的过程中,如果节点需要变更成为follower,需要在更新节点term和更新节点状态两个操作间添加lock保护,以避免脏数据读取。
bool raft_server::update_term(ulong term) {
if (term > state_->get_term()) {
{
// NOTE:
// There could be a race between `update_term` (let's say T1) and
// `handle_cli_req` (let's say T2) as follows:
//
// * The server was a leader at term X
// [T1] call `state_->set_term(Y)`
// [T2] call `state_->get_term()`
// [T2] write a log with term Y (which should be X).
// [T1] call `become_follower()`
// => now this server becomes a follower at term Y,
// but it still has the incorrect log with term Y.
//
// To avoid this issue, we acquire `cli_lock_`,
// and change `role_` first before setting the term.
std::lock_guard<std::mutex> ll(cli_lock_);
role_ = srv_role::follower;
state_->set_term(term);
}
state_->set_voted_for(-1);
state_->allow_election_timer(true);
election_completed_ = false;
.....该问题详细记录在了Github issue中,有兴趣可以参考。
版权声明:文章为作者辛勤劳动的成果,转载请注明作者与出处。