在优酷我们使用Redis Cluster构建了一整套内存存储系统,项目代号为蓝鲸。蓝鲸的设计目标是高效读写,所有数据都在内存中。蓝鲸的主要应用场景是cookie和大数据团队计算的数据,都具有较强的失效性。所以所有的数据都有过期时间。更准确的说蓝鲸其实是一个全内存的临时存储系统。
到目前为止集群规模逐渐增长到800+节点,即将达到作者建议的最大集群规模1000节点。我们发现随着集群规模的扩大带宽压力不断突出,并且RT方面也会略微升高。与一致性哈希构建的Redis集群不一样,Redis Cluster不能做成超大规模的集群,它适合作为中等规模集群的解决方案。
运维期间吞吐量与RT一直作为衡量集群稳定性的重要指标,这里把我们碰到的影响集群吞吐量与RT的一些问题与探索记录下来,希望对他人有所帮助。
单进程模型与主要负载
Redis采用单线程模型,除去bgsave与aof rewrite会另外新建进程外,所有的请求与操作都在主进程内完成。其中比较重量级的请求与操作类型有:
- 客户端请求
- 集群通讯
- 从节同步
- AOF文件
- 其它定时任务
Redis服务端采用Reactor设计模式,它是一种基于事件的编程模型,主要思想是将请求的处理流程划分成有序的事件序列,比如对于网络请求通常划分为:Accept new connections、Read input to buffer、Process request、 Response等几个事件。并在一个无限循环的EventLoop中不断的处理这些事件。更多关于Reactor,请参考wiki。
比较特别的是,Redis中还存在一种时间事件,它其实是定时任务,与请求事件一样,它同样在EventLoop中处理。Redis主线程的主要处理流程如下图:
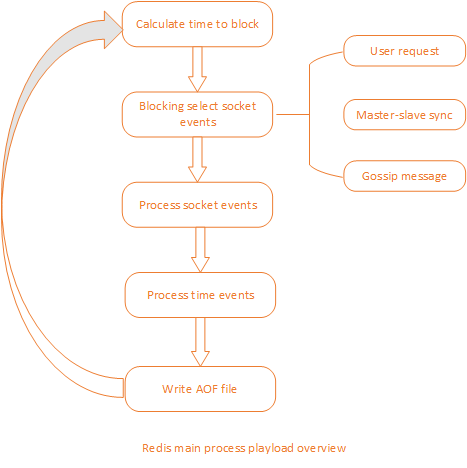
理解了Redis的单进程模型与主要负载情况,很容易明白,想要增加Redis吞吐量,只需要尽量降低其它任务的负载量就行了,所以提高Redis集群吞吐量的方式主要有:
适当调大cluster-node-timeout参数
我们发现当集群规模达到一定程度时,集群间消息通讯开销,是极其可观的。
集群通信机制
Redis集群采用无中心的方式,为了维护集群状态统一,节点之间需要互相交换消息。Redis采用交换消息的方式被称为==Gossip==,基本思想是节点之间互相交换信息最终所有节点达到一致,更多关于Gossip可参考wiki。
总结集群通信机制的一些要点:
- Who: 集群中每个节点
- When:定时发送,默认每隔一秒
- What:一个长度为16384的Bitmap与集群中其它节点状态的十分之一
如何理解集群中节点状态的十分之一?假如集群中有700个节点,十分之一就是70个节点状态,节点状态具体数据结构见下边代码:
typedef struct {
char nodename[REDIS_CLUSTER_NAMELEN]; /* 40 bytes*/
uint32_t ping_sent;
uint32_t pong_received;
char ip[REDIS_IP_STR_LEN]; /* IP address last time it was seen 46 bytes*/
uint16_t port; /* port last time it was seen */
uint16_t flags; /* node->flags copy */
uint16_t notused1; /* Some room for future improvements. */
uint32_t notused2;
} clusterMsgDataGossip;==我们将注意力放在数据包大小与流量上==,每个节点状态大小为104byte,所以对于700个节点的集群,这部分消息的大小为70*104=7280,大约为7KB。另外每个gossip消息还需要携带一个长度为16384的Bitmap,大小为2KB,所以每个Gossip消息大小大约为9KB。
随着集群规模的不断扩大,每台主机的流量不断增长,我们怀疑集群间通信的流量已经大于前端请求产生的流量,所以做了以下实验以明确集群流量状况。
实验过程
实验环境为:节点704,物理主机40台,每台物理主机有16个节点,集群采用一主一从模式,集群中节点cluster-node-timeout设置为30秒。
实验的大概思路为,分别截取一分钟时间内一个节点,在集群通信端口上,进入方向与出去方向的流量,并统计出消息条数,并最终计算出台主机因为集群间通讯产生的带宽开销。实验具体过程如下:
//集群通信端口进去方向流量实验
19:22 [root@hostname$ tcpflow -cp dst host 10.100.51.161 and dst port 17380 > in.log
tcpflow[32573]: listening on eth0
^Ctcpflow[32573]: terminating //terminating tcpflow after 1 minute
19:23 [root@hostname]$ du in.log
25924 in.log //node receives 25924 KB data in 1 minute
19:23 [root@hostname]$ cat in.log | grep ": RCmb" | wc -l
2706 //there are 2706 messages
//集群通信端口出去方向流量实验
18:22 [root@hostname]$ tcpflow -cp src host 10.100.51.161 and src port 17380 > out.log
tcpflow[31755]: listening on eth0
^Ctcpflow[31755]: terminating //terminating tcpflow after 1 minute
18:23 [root@hostname]$ du out.log
25700 out.log //node sends 25700 KB data in 1 minute
18:26 [root@hostname]$ cat out.log | grep ": RCmb" | wc -l
2747 //there are 2747 messages通过实验能看到进入方向与出去方向在60s内收到的数据包数量为2700多个。因为Redis规定每个节点每一秒只向一个节点发送数据包,所以正常情况每个节点平均60s会收到60个数据包,为什么会有这么大的差距?
原来考虑到Redis发送对象节点的选取是随机的,所以存在两个节点很久都没有交换消息的情况,为了保证集群状态能在较短时间内达到一致性,Redis规定==当两个节点超过cluster-node-timeout的一半时间没有交换消息时,下次心跳交换消息==。
解决了这个疑惑,接下来看带宽情况。先看Redis Cluster集群通信端口进入方向每台主机的每秒带宽为:
//因为每台主机有16个节点所以乘以16
cluster_ports_in = 25924 * 1024 * 8 * 16 / 60 = 56631842 bit/s = 54 MBit/s再看Redis Cluster集群通信端口出去方向每台主机的每秒带宽为:
cluster_ports_out = 25700 * 1024 * 8 * 16 / 60 = 56631842 bit/s = 53.5 MBit/s所以每台主机进入方向的带宽为:
in = cluster_ports_in + cluster_ports_out = 107.5MBit/s为什么需要加和
我们以节点A主动与节点B发生消息交换为例进行说明,交换过程如下图:

首先A随机一个端口向节点B的集群通讯端17380发送==PING==消息,之后节点B通过17380端口向节点A发送==PONG==消息,==PONG消息的内容与PING消息的内容相似,每个消息的大小也一样(9KB)==。同理当节点B主动与节点A发生消息交换时也是同样的过程。
可以看出对于节点A进入方向的带宽不仅包含集群通讯端口的还包含随机端口的带宽。而对于节点A进入方向随机端口的带宽,正是其它节点出去方向的带宽。所以每台主机进入方向的带宽为上边公式计算的加和。同理出去方带宽与进入方带宽一样为107.5MBit/s。
cluster-node-timeout对带宽的影响
集群中每台主机的带宽状况如下图:

每台主机的进出口带宽都大概在150MBit/s左右,其中集群通信带宽占107.5MBit/s,所以前端请求的带宽占用大概为45MBit/s。再来看当把==cluster-node-timeout==从20s调整到30s时,主机的带宽变化情况:
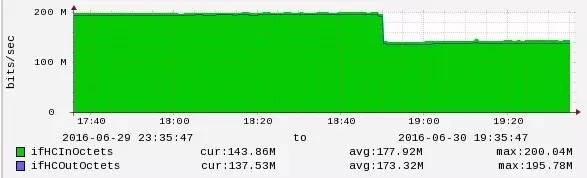
可以看到带宽下降50MBit/s,效果非常明显。
经过以上实验我们能得出两个结论:
- 集群间通信占用大量带宽资源
- 调整cluster-node-timeout参数能有效降低带宽
Redis Cluster判定节点为fail的机制
但是并不是==cluster-node-timeout==越大越好。当==cluster-node-timeou增大的时候集群判断节点fail的时间会增加,从而failover的时间窗口会增加==。集群判定节点为fail所需时间的计算公式如下:
cluster-node-timeout + cluster-node-timeout / 2 + 10当节点向失败节点发出==PING==消息,并且在==cluster-node-timeout==时间内还没有收到失败节点的PONG消息,此时判定它为==pfail==。==pfail==即部分失败,它是一种中间状态,该状态随着集群心跳不断传播。再经过一半==cluster-node-timeout==时间后,所有节点都与失败的节点发生过心跳并且把它标记为==pfail==。当然也可能不需要这么长时间,因为其它节点之间的心跳同样会传递==pfail==状态,这里姑且以最大时间计算。
Redis Cluster规定当集群中超过一半以上节点认为一个节点为==pfail==状态时,会把它标记为==fail==状态,并广播给其他所有节点。对于每个节点而言平均一秒钟收到一个心跳包,每次心跳都会携带随机的十分之一的节点个数。所以现在问题抽像为经过多长时间一个节点会积累到一半的==pfail==状态数。这是一个概率问题,因为个人并不擅长概率计算,这里直接取了一个较大概率能满足条件的数值10。
==所以上述公式不是达到这么长时间一定会判定节点为fail,而是经过这么长时间集群有很大概率会判定节点fail==。
Redis Cluster默认cluster-node-timeout为15s,我们将它设置成了30s。也就是说700节点的集群,集群间带宽开销为104.5MBit/s,判定节点失败时间窗口大概为55s,实际上==大多数情况都小于55s==的啦,因为上边的计算都是按照高位时间估算的。
总而言之,对于大的Redis集群cluster-node-timeout参数的需要谨慎设定。
主节点写命令传播
Redis中主节点的每个写命令传播到以下三个地方
- 本地AOF文件,以持久化持数据
- 主节点的所有从节点,以保持主从数据同步
- 本节点的repl_backlog缓存,主要为了支持部分同步功能,详见官网Replcation文档Partial resynchronization部分。
//redis-3.0.0 redis.c
/* Propagate the specified command (in the context of the specified database id)
* to AOF and Slaves.
*
* flags are an xor between:
* + REDIS_PROPAGATE_NONE (no propagation of command at all)
* + REDIS_PROPAGATE_AOF (propagate into the AOF file if is enabled)
* + REDIS_PROPAGATE_REPL (propagate into the replication link)
*/
void propagate(struct redisCommand *cmd, int dbid, robj **argv, int argc,
int flags)
{
if (server.aof_state != REDIS_AOF_OFF && flags & REDIS_PROPAGATE_AOF)
feedAppendOnlyFile(cmd,dbid,argv,argc);
if (flags & REDIS_PROPAGATE_REPL)
replicationFeedSlaves(server.slaves,dbid,argv,argc);
}其中repl_backlog部分传播在replicationFeedSlaves函数中完成。
减少从节点的数量
高可用的集群不应该出现单点,所以Redis集群一般都会是主从模式。Redis的主从同步机制是所有的主节点的写请求,会同步到所有的从节点。如果没有从节点,对于主节点来说,它只需要处理该请求即可。但对于有N个从节点的主节点来说,==它需要额外的将请求传播给N个从节点。请注意这里是对于每个写请求都会这样处理==。显而易见从节点的数量对主节点的吞吐量的影响是比较大的,我们采用的是一主一从模式。
因为从节点不需要同步数据,生产环境中观察主节点的CPU占用率要比从节点机器要高,这对这条结论起到了佐证的作用。
关闭AOF功能
如果开启AOF功能,==每个写请求==都会Append到本地AOF文件中,虽然Linux中写文件操作会利用到==操作系统缓存机制==,但是如果关闭AOF功能主线程中省去了写AOF文件的操作,显然会对吞吐量的增加有帮助。
AOF是Redis的一种持久化方式,如果关闭了AOF功能怎么保证数据的安全性。我们的做法是定时在从节点BGSAVE。当然具体采用何种策略需要结合具体情况来决定。
去掉频繁的Cluster nodes命令
在运维过程中发现前端请求的平均RT增加不少,大概50%左右。通过一番调研发现是因为==频繁的cluster nodes==命令导致的。
当时集群规模为500+节点,==cluster nodes==命令返回的结果大小有==103KB==。cluster nodes命令的频率为,每隔20s向集群所有节点发送。
hz参数
Redis会定时做一些任务,任务频率由hz参数规定,定时任务主要包含:
- 主动清除过期数据
- 对数据库进行渐式Rehash
- 处理客户端超时
- 更新请求统计信息
- 发送集群心跳包
- 发送主从心跳
以下是作者对于hz参数的介绍:
# Redis calls an internal function to perform many background tasks, like
# closing connections of clients in timeout, purging expired keys that are
# never requested, and so forth.
#
# Not all tasks are performed with the same frequency, but Redis checks for
# tasks to perform according to the specified "hz" value.
#
# By default "hz" is set to 10. Raising the value will use more CPU when
# Redis is idle, but at the same time will make Redis more responsive when
# there are many keys expiring at the same time, and timeouts may be
# handled with more precision.
#
# The range is between 1 and 500, however a value over 100 is usually not
# a good idea. Most users should use the default of 10 and raise this up to
# 100 only in environments where very low latency is required.我们没有修改hz参数的经验,由于其复杂性,并且在hz默认值10的情况下,理论上不会对Redis吞吐量产生太大影响,建议没有经验的情况下不要修改该参数。
写在最后
以上是我们使用Redis cluster的一点经验跟探索,希望对他人有所帮助。
关于Redis Cluster可以参考官方的两篇文档:
版权声明:文章为作者辛勤劳动的成果,转载请注明作者与出处。