我们开源了Raftkeeper,项目地址:https://github.com/JDRaftKeeper/RaftKeeper,欢迎大家体验使用并给予宝贵建议。
一、背景介绍
成百上千台服务器组成的分布式系统中,服务器故障或网络抖动会随时发生,有时会导致严重的系统崩溃,为解决如上问题,雅虎开源了ZooKeeper分布式协调服务并在2010年成为Apache顶级项目,是Hadoop、HBase和ClickHouse的关键组件。
在ClickHouse应用ZooKeeper的场景中,因无法突破高吞吐写入和低延时数据复制的瓶颈,京东零售智能平台部OLAP团队基于ClickHouse研发RaftKeeper(采用Raft协议C++实现的分布式共识服务),为了便利行业伙伴对新技术的应用,现已面向社区实现全面开源,诚邀大家体验新技术!
二、技术架构
RaftKeeper基于Raft协议,提供顺序一致性保证,同时保证session内严格的读写顺序性,即:同一个session内的请求的响应顺序严格有序。RaftKeeper数据常驻内存,提供了snapshot + operation log的数据持久化能力;执行框架上采用了流水线和批量执行的方式,极大提升系统吞吐量。
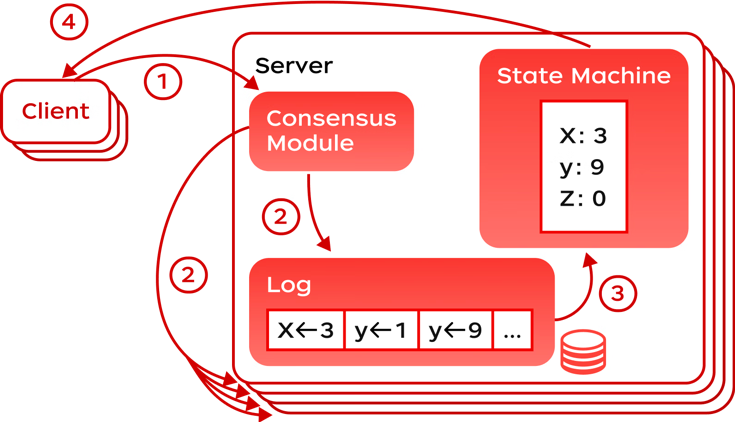
三、核心优势
1、高性能:RaftKeeper提供2倍以上的吞吐量和容量,突破了分布式系统协调服务的处理能力限制,延迟时间减半,请求更加平稳,资源消耗更低,在性能要求更高的场景中表现更优异。参考:Benchmark。

2、高可用:提供5个9的可用性,杜绝单点故障影响,保障数据写入后永不丢失,支持跨机房数据协调。
3、全面兼容ZooKeeper:兼容ZooKeeper的各类客户端、可视化工具和监控工具,提供数据转换工具可以将Zookeeper的数据转换成RaftKeeper存储格式,实现ZooKeeper无感切换。
四、优化路径
RaftKeeper是一个分布式服务,需要保证日志在多个节点间的顺序性,因此需要串行化处理,传统的并行化性能优化的方式并不完全适用。
Raft论文中提到性能优化的主要手段是批量执行和流水线执行,在RaftKeeper的开发实践中,我们也着重在这两方面进行了大量优化。
在日志和状态机模块中,针对频繁访问的热Log数据,根据Log顺序性特点,我们设计了环形缓存数组提供高速读取。针对状态机中的哈希表,为了避免扩容带来的卡顿,我们设计了分段哈希表的数据结构,让服务更加平稳,可以存储更多的ZNode。其他如读写IO、多线程锁粒度层面也做了大量优化。
最后,也得益于eBay优秀开源框架NuRaft和ClickHouse的高性能基础类库,才让RaftKeeper拥有强悍的性能。
五、应用场景
RaftKeeper已在京东零售多个场景中长时间大规模应用,在多次大促中验证技术可靠性。
ClickHouse场景:突破了元数据管理的瓶颈,大幅缩短了如刷岗等海量导数的时间,可以部署更大规模的集群避免小集群重复存储问题,同时也支持异地跨机房双活方案;
HBase场景:支持30万客户端同时连接,更低更平稳的延时提供了更快更稳定的服务。
同时RaftKeeper支持更多场景:集群管理、节点协调、配置中心、命名服务等。
本作品采用 知识共享署名 4.0 国际许可协议 进行许可, 转载时请注明原文链接。