ClickHouse is well-known for its excellent performance, and optimizing the performance of a database is a massive systemic project. This article focuses on the basic data structures within ClickHouse to reveal just a small part of the performance optimization iceberg.
In software engineering, not all execution paths need to be optimized; only the critical execution paths require significant optimization efforts. For the database field, the critical execution path can be summarized in one sentence: the function or code that needs to be executed for every row of data in a query. Basic data types form the foundation of algorithms on the critical execution path, so optimizing them has a significant impact on performance.
PS: The discussion in this article is based on ClickHouse version 24.1.
Last updated: June 3, 2024
1. Overview of Basic Data Structures
Based on practical experience, approximately half of the columns are of string type, making strings an important basic data type. ClickHouse is a columnar database, and data processing is also done in a columnar manner. The data of each column needs to be represented using arrays, making arrays another important data type.
This article discusses the important basic data types within ClickHouse: StringRef and PodArray.
2. StringRef
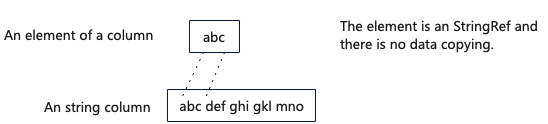
StringRef works similarly to std::string_view in that it can represent a reference to a sequence of characters. For example, given the string str = "abcdef", StringRef(str.data() + 1, 2) represents “bc”. Note that StringRef does not actually copy “bc”.
StringRef is widely used in the critical execution paths of ClickHouse, such as in the in-memory representation of String type columns (ColumnString), and in key data structures like HashMap used by Aggregate and Join operators. The diagram below illustrates the use of StringRef in String type columns, avoiding data copying.
Due to its widespread application, ClickHouse has deeply optimized StringRef.
The most important operation for StringRef is equality checking, so the memequalWide function, which checks for equality, is a key optimization target. Instead of comparing each character one by one, ClickHouse uses a batch processing approach to determine if two strings are equal.
2.1 size <= 16
When the string length is less than or equal to 16, the strings are handled in the following four cases based on their length. The main idea is to treat the strings as larger data types (integers) for comparison to save CPU cycles. The reason for this approach is that a 64-bit CPU can compare 8 characters in a single operation, and treating the strings as larger data types minimizes the number of comparisons needed.
Since not all sizes can be evenly divided by the length of the data type, after comparing the first n bytes, the remaining n bytes are compared again. This is a clever design because two comparisons can cover all the characters.

2.2 size > 16

- For parts greater than 64 bytes,
compare64is used, which is a combination of fourcompare8operations. - For the remaining parts that can be evenly divided by 16,
compare8is used.compare8is a vector comparison function that uses the SSE2 instruction set, comparing two 16-character strings at once. - The
compare8function is also used to compare the last 16 characters of the remaining part.
2.3 Function compare8
Using the SSE2 instruction set (SIMD instructions), two 16-character data segments are compared for equality in a single operation.
inline bool compareSSE2(const char * p1, const char * p2)
{
return 0xFFFF == _mm_movemask_epi8( // 4) translate _m128i to int32
_mm_cmpeq_epi8( // 3) Compare the 2 Strings
_mm_loadu_si128(reinterpret_cast<const __m128i *>(p1)), // 1) Load String 1 to reigster
_mm_loadu_si128(reinterpret_cast<const __m128i *>(p2)))); // 2) Load String 2 to reigster
}3. PodArray
PodArray is ClickHouse’s custom vector. Almost all data type columns in ClickHouse use PodArray for their in-memory representation, so ClickHouse has also optimized PodArray extensively.
Most of the detailed optimizations are scenario-specific, so it is important to clarify the application scenarios for which PodArray is designed. It is mainly used for storing columnar data. In ClickHouse, columnar data is divided into small chunks in memory, with the default chunk length being around 65,000. To summarize, PodArray is mainly used for storing large amounts of data in a vector-like data structure.
3.1 Support for use of stack memory
Because stack space is limited, traditional dynamic array structures like std::vector allocate data on the heap. This design is versatile but introduces an additional indirection for data access, which is detrimental to cache line hit rates. To address this, ClickHouse provides a stack memory allocation solution called PODArrayWithStackMemory.
Its working principle is as follows: PodArray inherits from AllocatorWithStackMemory. AllocatorWithStackMemory is a memory allocator characterized by using stack space when the required memory is below a certain threshold. When the required memory exceeds this threshold, it allocates space on the heap and copies the data from the stack to the heap.
3.2 Padding
PaddedPodArray is a PodArray with padding, where some blank memory space is added on both sides. This memory space is initialized to 0. Its memory structure is as follows:

3.2.1 left padding
There are many variable-length data types in ClickHouse. Variable-length data types refer to those where each value’s length is not fixed, such as String. For such data structures, it is necessary to store an offset array and a data array when storing them, as shown below:

When it is necessary to retrieve a specific element, the length of the element needs to be calculated. The calculation method is as follows:
/// Size of i-th element, including terminating zero.
size_t ALWAYS_INLINE sizeAt(ssize_t i) const
{
auto end_offset = i == 0 ? 0 : offsets[i - 1];
return offsets[i] - end_offset;
}Each time, it is necessary to check if i is 0. The if statement significantly affects the CPU instruction cache hit rate and prevents the compiler from performing automatic vectorization, thereby impacting performance.
With the introduction of left padding, the code can be optimized as follows:
/// Size of i-th element, including terminating zero.
size_t ALWAYS_INLINE sizeAt(ssize_t i) const
{
return offsets[i] - offsets[i - 1];
}By removing the if statement, the impact on the CPU instruction cache hit rate is eliminated. Additionally, if the loop is called repeatedly, it can trigger the compiler’s automatic vectorization.
PS: For more information on the impact of CPU instruction cache hit rate on performance, refer to: ClickHouse Internals (5) Hardware-Based Performance Optimization
PS: Conditions for triggering compiler automatic vectorization: requirements-for-vectorizable-loops
3.2.2 right padding
The primary purpose of the right padding design is to enhance the efficiency of SIMD instruction functions and simplify coding. For example, a simple SSE version of a memory copy function, without right padding, might be implemented as follows:
inline void memcpy(char * __restrict dst, const char * __restrict src, size_t n)
{
auto aligned_n = n / 16 * 16;
auto left = n - aligned_n;
while (aligned_n > 0)
{
_mm_storeu_si128(reinterpret_cast<__m128i *>(dst),
_mm_loadu_si128(reinterpret_cast<const __m128i *>(src)));
dst += 16;
src += 16;
aligned_n -= 16;
}
::memcpy(dst, src, left);
}However, if both dst and src have 15 bytes of right padding, the implementation can be optimized as follows:
inline void memcpy(char * __restrict dst, const char * __restrict src, size_t n)
{
while (n > 0)
{
_mm_storeu_si128(reinterpret_cast<__m128i *>(dst),
_mm_loadu_si128(reinterpret_cast<const __m128i *>(src)));
dst += 16;
src += 16;
n -= 16;
}
// No additional handling for the ending part is needed here.
}3.3 Function emplace_back
The emplace_back function of PodArray constructs the object to be inserted directly in the memory space at the end, which reduces the overhead of an extra memory copy compared to constructing it in advance and then copying it. This optimization is similar to the emplace_back function of std::vector.
template <typename... Args>
void emplace_back(Args &&... args) /// NOLINT
{
if (unlikely(this->c_end + sizeof(T) > this->c_end_of_storage))
this->reserveForNextSize();
new (t_end()) T(std::forward<Args>(args)...); /// Constructing the object at the end reduces the overhead of data copying.
this->c_end += sizeof(T);
}The placement new operator is used when creating objects, which allows objects to be created at a specified memory address. For more information on the placement new operator, please refer to: Stack Overflow
This work is licensed under a Creative Commons Attribution 4.0 International License. When redistributing, please include the original link.