Apache Kylin是一款国人主导的优秀的OLAP引擎,工作中对Kylin有大规模的使用,尝试总结Kylin核心技术,本文是第一篇,偏向数据模型方面。
数据模型概览
本质上Kylin将二维表(Hive表)Cube化,然后将Cube存储到HBase表中。

Cube in Kylin
首先需要明确一个概念,在多维分析的领域中表的列被分成维度与度量两类,其中维度可以被作为查询条件和Group by的对象,比如像城市、类别等等列;度量一般表示特定维度值下的度量值,比如像价格、数量等列。
Kylin中的Cube其实就是传统数据库中Cube的概念。这里举个例子做个简单的介绍。假设一个二维表的维度为:。那么它的Cube可以用图2表示。
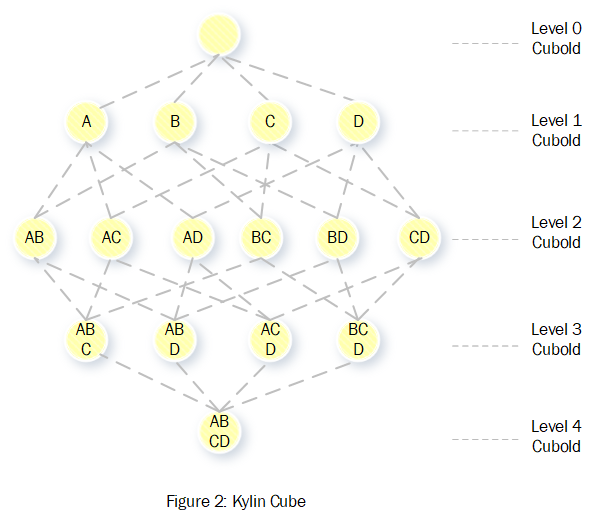
在Kylin中上图每个节点都被称为一个CuboId,CuboId按照层次划分,每个层次表示CuboId由几个维度组成,整个Cube包含2的N次方个CuboId。
CuboId表示固定列的数据数据集合,比如组成的CuboId的数据集合等价于以下SQL的数据集合:
select A, B, sum(M), sum(N) from table group by A, B可以看出在Kylin中的数据是按照维度进行了预聚合后的数据,这也是Kylin在海量数据集下依然能够亚秒时间内完成查询的关键所在。
Cube in HBase
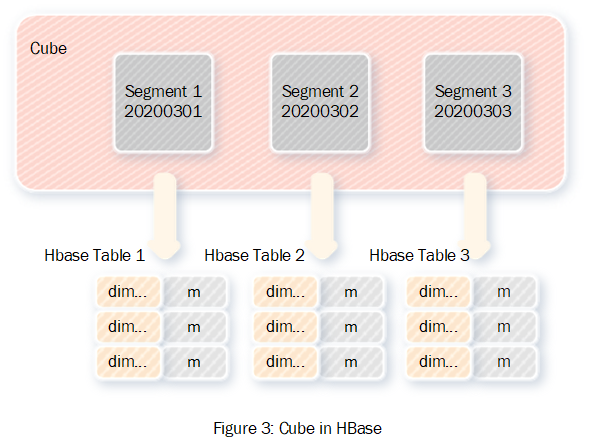
一般来说Cube会按照时间划分为多个segment,每个segment对应一个HBase表,多个segment的数据格式是同构的,图3展示了Cube与HBase表的对应关系。
接下来看下每个segment内部的数据格式,因为维度列需要作为查找条件,所以适合用来组成rowkey;度量列适合作为HBase值来存储。其中度量列可以共用一个列簇,也可以划分为多个列簇,图4展示了数据序列化格式。

我们将注意力放到rowkey的组成上,这也是数据存储部分的核心点。图中可以看到rowkey包含三部分:ShardNum、CuboId、Encoded_Dims。因为rowkey本质上是一个二进制的值,所以为了区分每个部分的值,ShardNum、CuboId和每个编码后的维度,它们需要是定长的。接下来分析这三个部分。
首先CuboId,我们可以站在kylin设计者的角度进行分析,当用户发起查询的时候,会提取SQL中where和group by后的列,这些列是此次查询涉及到的所有维度,进而可以确定CuboId,所以rowkey中应该包含CuboId信息。
其次Shard_Num部分,Shard_Num的设计目的是将同一个CuboId的数据分散到多个Region中,这样查询的时候能利用更多HBase节点的计算能力。Kylin中的查询具有一个特点每个不包含子查询的查询将只命中一个CuboId。假设rowkey中不包含ShardNum部分,因为HBase数据按照rowkey大小排序,并且连续存放的特点,那么一个CuboId中的数据将集中在少数甚至一个Region中,所以查询的时候将只有少数节点进行工作。反之通过Shard_Num将同一个CuboId中的数据分散到多个Region中,这样查询时将利用更多HBase节点的计算能力。
最后Encoded_Dims部分,这部分信息是维度列值信息,这里有两点需要说明,一个是因为rowkey的排序特性,所以多个维度的顺序需要固定,kylin在定义Cube的时候确定了列的顺序;二是所有的维度进行了编码,下文会详细介绍。
CuboId
这里详细介绍下Kylin中的CuboId,从上文中我们得知CuboId是组成rowkey的第二个部分,为了达到数据在HBase中有序的目的,CuboId必须是定长的,其实在Kylin中CuboId是一个长度为8个字节的长整型数值。
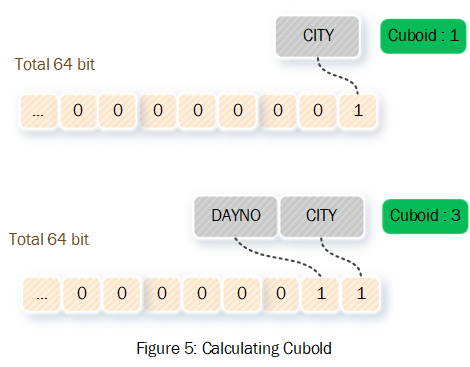
为了介绍CuboId与维度之间的计算方式,重新假设一个Cube,其维度为DAYNO CITY,并且维度顺序为DAYNO CITY。
那么该Cube只需要Long的Bit形式的最后两位来表示对应的CuboId,其中Bit数组最后一位表示CITY,倒数第二为表示DAYNO,比如:仅由CITY组成的cuboId为1;由DAYNO和CITYY组成的cuboId为3。
Shard_Num
Shard_Num是Kylin在分布式系统中组织数据的关键设计点,通过分析它可以洞悉kylin数据分布的算法。在数据构建阶段Kylin估算出Segment中每个CuboId的数据量,所有CuboId数据量的总和就是该segment的数据量,进而计算出该segment需要划分成多少分片,也就是HBase中Region的数量。
接下来的重点是如何切分CuboId中的数据,我们可以首先站在Kylin设计者的角度思考,因为一条查询只会涉及到一个CuboId,所以需要对它进行切分以利用更多节点的计算能力,但是对于只有几条几百条数据的CuboId是没必要切分的。
具体的CuboId切分算法是:小CuboId不分片,其应该放到哪个分片(Region)上,计算公式为:
hash(CuboId) % TotalShard大CuboId分片它的分布计算公式为:
初始分片:stardShardNum = hash(CuboId) % TotalShard
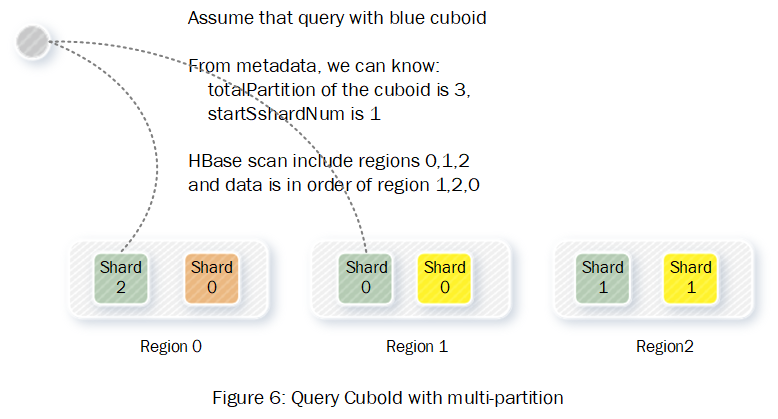
其余分片:cuboid_Partition_N = (N + stardShardNum) % TotalShard我们从查询的角度看下以上数据分布算法的可行性。对于小的CuboId因为只有在一个分片上是可以通过元数据直接定位到数据位置的。对于大的CuboId,它的数据散列在不同的分片,但是按照算法同样可以保证同一个cuboId数据的有序性,具体计算方式可参考图6:
Encoded_Dims
组成HBase rowkey的维度组合,并不直接存储每个维度的值,而是编码成整数,这里有个关键的隐含信息:整数是定长的。这样做的目的是为了保证数据的可查找性。为了方便理解,这里举个例子:假设有A,B两个维度组成的CuboId,如果rowkey存储的是原始值则以下两条数据将有歧义(ab, c)和(a, bc)。
数据编码就需要一个字典,Kylin中采用了Trie树组成的森林构成的字典,详细可以参考官方文档。
值得一提的是由于日期的特殊性,它的字典编码采用特殊的算法:当前日期距离 0000-1-1的差值,比如:
0000-1-1 = 0
2018-5-1 = 1431172
9999-12-31 = 3652426这种算法的好处:一是减小了存储空间,二是统一了全局编码,免去了合并字典时需要重新编码的代价。
小结
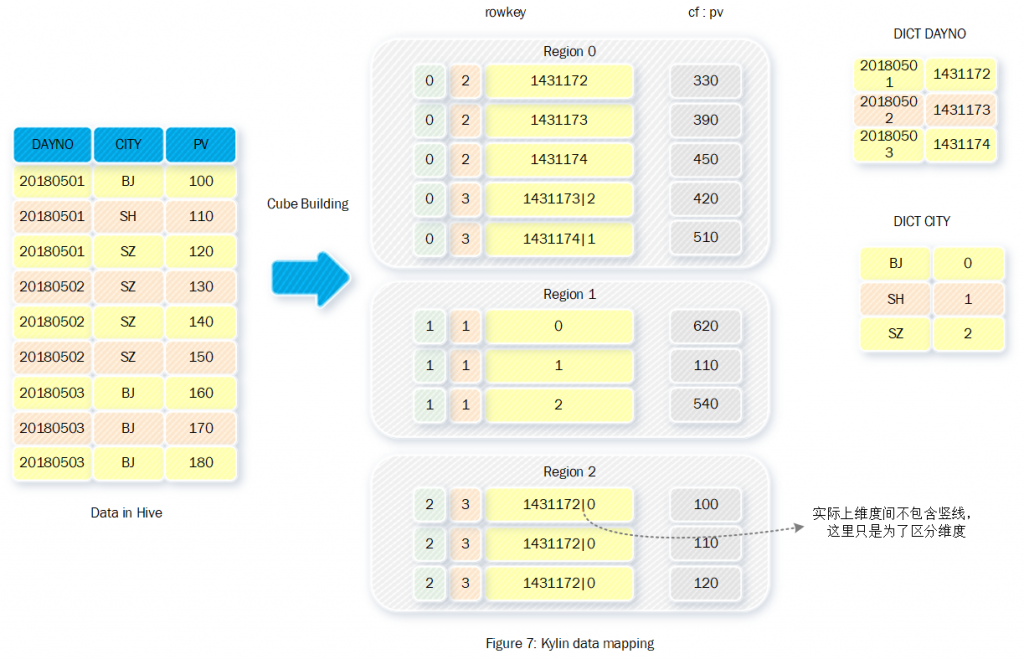
本文总结了Kylin数据模型,其实也就是数据如何从Hive表转换成HBase表的过程,图7展示了一个Hive表和HBase表的数据映射关系:
本作品采用 知识共享署名 4.0 国际许可协议 进行许可, 转载时请注明原文链接。